Benchmarking XML Parsers
May 5, 1999
A performance comparison of six stream-oriented XML parsers
This article compares the performance of six implementations of a single program that processes XML. Each implementation uses a different XML parser and four different languages are used: C, Java, Perl, and Python. Only a single parser is tested for Perl and Python, but two parsers each are tested for C and Java.
All of these parsers run under Linux, and all are stream-oriented. An application must provide callbacks (or their equivalent) in order to receive information back from the parser. While some of them have a validating mode, all the parsers were run as non-validating parsers. When I say that a single program was implemented six times, I mean that each implementation produces (or should produce) exactly the same output for a given input document. But as long as that constraint was met, I attempted to write each in the most efficient manner for the given language and parser.
Full disclosure
But first, let me come clean. I'm the maintainer of one of the parsers measured here, the Perl module XML::Parser. I have an interest in making it look good. But I'm providing here everything I used to come up with my numbers. So you're welcome to download what I've got and try it out for yourself. Also, since I'm more experienced in Perl and C than Java and Python, gurus of those two languages may want to comb through the implementations written in them, checking for newbie mistakes.
What motivated me to run this experiment was a discussion on the performance (or lack thereof) of XML::Parser on the Perl-XML mailing list. I asked the question, "How does XML::Parser compare to the competition?" Either I got no answers or the answers were like comparing apples and oranges. (For instance, comparing XML::Parser to the Unix grep utility.) So I decided to take one of the sample programs contained in the XML::Parser distribution, XMLstats, and implement it using different parsers.
This section describes in detail how I went about testing parser performance in C, Java, Perl, and Python on a Linux system. If you are so inclined, run the test yourself on your own system.
The humble XMLstats program
I described this program in my September article on this site. It produces a top-down statistical report on the elements in an XML document: the number of occurrences; a breakdown of the number of children, parents, and attributes; and character count. I think this is a good exercise for a parser since:
- It does something useful.
- It processes every start tag and piece of text.
- It doesn't do too much work beyond parsing.
In any case, it was at hand and I didn't have to invent some other kind of made-up application.
The main work that this program has to do outside of parsing is order the elements in a top-down fashion, yet account for the fact that element containment graphs may have cycles.
Test environment
I ran these tests on my Gateway Solo 5150 laptop with Red Hat 5.2 Linux installed. This is a Pentium II machine with 64 megabytes of RAM. The CPUinfo reports that it tests at 232.65 Bogomips.
The C compiler is GCC 2.7.2.3, the one that came with Red Hat 5.2. I'm using the pre-release version 1.2 Java Development Kit from Blackdown. The Perl version is 5.005_02, and Python 1.5.1 is installed on my machine.
Test documents
All the test documents descended from REC-xml-19980210.xml, the XML version of the XML specification. The only change from it in REC.xml was the removal of the system identifier, spec.dtd, from the DOCTYPE declaration. Some of the parsers wanted it to be there if you declared it, even in non-validating mode.
The other documents are mechanically expanded versions of REC.xml. In the case of med.xml and big.xml, the contents of the root element were just repeated, 8 and 32 times respectively. Of course, this would make them invalid even without an element model since we've repeated ID attributes. (Assuming attributes named "id" are meant to be ID attributes.) But they're still well-formed.
In the case of chrmed.xml and chrbig.xml, just the text contents were repeated, 8 and 32 times respectively. This was accomplished with the use of the scale.pl Perl script. Because of the way these were generated, they have no prolog and entities in the original document are pre-expanded.
| REC | chrmed | med | chrbig | big | |
|---|---|---|---|---|---|
| size (bytes) | 159339 | 893821 | 1264240 | 3417181 | 5052472 |
| markup density | 34% | 6% | 33% | 2% | 33% |
It would have been interesting to see how a document closer to RDF would have fared, but I ran out of time. I'm hoping that this article will instigate other benchmarks that look at things like RDF.
Methodology and results
The performance of an implementation on each test case was measured using the Unix
time command, with output being sent to the /dev/null data sink. Actually
each case was measured three times and the average was taken. And these measurements
didn't
start until after each implementation had a chance to position itself into the physical
memory working set.
This command delivers three timing numbers, processor seconds allocated to the process (user time), operating system processor seconds spent in service of the process (sys time), and actual elapsed time (real time).
To avoid errors due to hand transcription, the entire test process was automated using this Perl script. While this script was running, no other activity was demanded from my laptop.
XML parser performance statistics

The competitors
Four of the parsers are either written by or based on the work of James Clark. Clark wrote the Java XP parser and the C-Expat parser. Both the Perl and Python parsers used here are based on Expat.
Trying to get each implementation to produce exactly the same results exposed some bugs in the original XMLstats program. One of those bugs was that XMLstats was counting UTF8 bytes instead of characters when it reported character statistics. Another was that it didn't count all the white space that was part of mixed content. So the XMLstats program here is not the same as the one in the XML::Parser distribution.
C-Expat
While two of the other parsers in this test are built on top of James Clark's C-Expat parser, this example uses it directly. I'm using the test version of Expat, identified as "Version 19990307."
Although there is a hash table implementation in Expat, it's not part of the public interface. So I have included in the Util directory, a hash implementation that I created several years ago. It draws heavily on Larry Wall's implementation of hashes in Perl. This is the first public distribution of this package.
RXP
RXP is a parser produced by Richard Tobin of Language Technology Group at the University of Edinburgh. I'm using version 1.0 that I obtained from Richard's RXP web site.
RXP is stream-oriented, but instead of using callbacks, the application drives the main loop, asking the parser to give it the "next bit" it recognizes. Different flavors of bits are associated with different kinds of markup.
RXP has a validating mode, which wasn't used in this test.
Java-XP
I'm using XP version 0.4. The latest version of XP is available from James Clark's FTP site.
Although XP provides a SAX interface, I chose to use the native XP interface, in which your handlers are supplied as method overrides on the base ApplicationImpl class. I use several utility classes, like TreeMap, that only come with JDK 1.2.
Java-XML4J
This is Version 2.0.2 of IBM's XML parser for Java. I got this from the CD that IBM distributed to attendees of Xtech99, but you should be able to download a copy from somewhere on their alphaWorks web site. This parser has a validating mode.
This uses a SAX interface. So if you want to look at another SAX-based Java parser, you can probably use this with minimal change.
Perl
This is using XML::Parser version 2.23, which hasn't been released yet as I'm writing this, but may very well be released by the time you read this. The latest version of XML::Parser may be obtained from CPAN.
XML::Parser is built on top of James Clark's Expat parser.
Python
I'm using Pyexpat, another parser based on the Expat parser. There are several XML parsers for Python, many of which you get from the XML package put together by the XML special interest group at Python.org. I am using the Pyexpat parser from the 0.5 distribution of that package.
Conclusion
I'm hoping that other folks will take the package and try it out in different environments. (Perhaps someone will run it on NT and create an implementation for Microsoft's parser.) Also I'm hoping that others will contribute other kinds of tests, which we can post on XML.com. I'd like to see a test that was closer to XML's use for data communication. I expect in such cases that the markup density would be very high.
I've provided the programs and data files used in this program for anyone to download. (Xmlbench.tar.gz—1.98 megabytes in size. It is a tar file archive compressed with GNU zip.)
We tested six XML parsers that run on a Linux system: two C parsers (C-Expat and RXP), two Java parsers (Java XP and IBM's Java XML4J) and implementations in Perl and Python based on the Expat parser. Four of the six parsers rely on James Clark's Expat parser.
The test consisted on a single program that I called XMLstats because it reads an XML document and produces a report detailing the elements of those documents. I wrote the program in C, Java, Perl, and Python, using as best I knew how the best features of each language to do the same job. I ran the XMLstats program on five different XML test documents. All of the documents were derived from the XML 1.0 Recommendation. The file rec.xml is that document, which is about 160K in size. The med.xml is 6 times the size of rec.xml and big.xml is 32 times that size (literally, the Recommendation repeated 6 and 32 times.) chrmed.xml and chrbig.xml contain just the text contents of rec.xml repeated 6 and 32 times.)
The performance data generated by these tests is summarized in Table 1.
Table 1. XML Parser Performance Chart
| REC | chrmed | med | chrbig | big | |
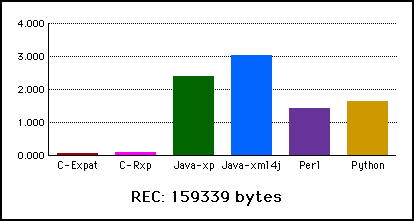
| C-Expat | 0.050 | 0.110 | 0.380 | 0.340 | 1.480 |
| C-Rxp | 0.100 | 0.320 | 0.740 | 1.060 | 2.937 |
| Java-xp | 2.400 | 2.693 | 4.770 | 4.010 | 12.587 |
| Java-xml4j | 3.033 | 3.470 | 6.770 | 5.280 | 19.230 |
| Perl | 1.413 | 3.420 | 8.410 | 10.750 | 32.357 |
| Python | 1.650 | 4.797 | 12.183 | 15.893 | 48.473 |
|
Figure 1. Comparison of Six XML Parsers Processing rec.xml. |
|
There aren't really many surprises. The C parsers (especially Expat) are very fast, the script-language parsers are slow, and the Java parsers occupy a middleground for larger documents. However for smaller documents (less than .5 megabytes), the Perl and Python parsers are actually faster than either Java parser tested.
Figure 1 graphs the performance of six parsers for rec.xml file. In this sample, both Java parsers are the slowest of the six. In Figure 2, which tests a larger sample, the Python parser is the slowest, but the two Java parsers and the Perl and Python parsers are very similar in speed. In both tests, the C parsers are extremely fast.
| Figure 2. Comparison of Six XML Parsers Processing chrmed.xml. |

|
Figure 3 graphs the performance of all six parsers against each of the five test files. Note that the Java parsers do much better on larger files than the Perl and Python implementations.
These tests only measure execution performance. Note that sometimes programmer performance is more important than parser performance. I have no numbers, but I can report that for ease of implementation, the Perl and Python programs were easiest to write, the Java programs less so, and the C programs were the most difficult.
| Figure 3. Comparison of Six XML Parsers Processing Each Test File. |

|
If you are interested in the details of how this test was put together, read the companion article "Constructing the XML Parser Benchmark."