Versa: Path-Based RDF Query Language
July 20, 2005
As interest in a standardized RDF query language reaches a feverish pitch, there are some fundamental approaches and patterns that are noteworthy. Versa is an RDF query language at the opposing end of the mainstream of RDF query languages, many of which are influenced, at least syntactically, by SQL. Versa's design was motivated primarily by XPath. This article discusses the fundamentals of Versa with an eye to emphasize and augment similarities with XPath and the aspects of SPARQL that are directly relevant.
Versa is a query language designed for the specific purpose of extracting information from an RDF graph in a very modular way. A Versa query facilitates the isolation of resources, and their associated property values through specific patterns and constraints as specified by a Versa expression (somewhat reminiscent of XPath expressions and regular expressions). A Versa query is performed by submitting a Versa expression to a Versa query processor associated with an RDF graph from which the user wishes to extract information. A Versa expression is one of the following:
- Nested (parenthesized) expressions
- Literals (instances of Versa data types)
- Variable References
- Particles (syntactic sugar): "*" or "."
- Traversal Expressions
- Function Calls
Literals
Versa models RDF literal data with the following set of data types (any of which can be returned as the result of evaluating a Versa expression).
Resources
A Versa resource is a string that represents the URI (Universal Resource Identifier) of an RDF resource in the underlying RDF graph. A Versa resource is expressed in one of two forms: as a QName (defined by the XML Namespaces specification) or a fully expressed URI as a quoted string preceded by the "u" character. This is somewhat analogous to Notation 3's use of QNames and "<" , ">". Versa does not distinguish between regular resources and blank nodes in query expressions. Blank nodes can be addressed the same as any other. Though this may seem counterintuitive to their impermanent nature, there are often real world scenarios where addressability is more important than anonymity, especially where response time is a factor.
Strings
A Versa string is simply a sequence of zero or more characters. Strings are expressed within Versa by enclosing them with single or double quotes. In order to allow the quote characters themselves to be included within a string, Versa provides a means to escape quotes by using the "\" character. The following is an example of using the "\" character to allow the inclusion of a quote character within a string: "This document\'s subject is Versa"
Numbers
A Versa number is a literal that represents a numerical value.
Boolean
A boolean represents a literal value of "true" or "false." The character "*" is provided as the short form for "true."
Sets
A Versa set follows from the definition of a set in the mathematical sense: a collection of distinct elements having specific common properties. Members of a set consist of: literals, resources, (other) sets, and lists.
Lists
A Versa list is a collection of elements (not necessarily distinct) which can be any one of: literals, resources, (other lists), and sets.
Versa Context
Often, Versa expressions are evaluated with respect to a context. A Versa context is related to an XPath context (and is comprised of similar parts). As a refresher, an XPath context consists of:
- a node (the context node)
- a pair of nonzero positive integers (the context position and the context size)
- a set of variable bindings
- a function library
- the set of namespace declarations in scope for the expression
The formal definition of a Versa Context is below:
Many Versa constructs are evaluated with regard to a context. The context is a value of any data type, and it can always be referred to explicitly in an expression using the token ".".
You can think of a Versa context as an XPath context with a literal value instead of a context node, without a position and size, and associated with a named graph or the entire underlying RDF model. This concept of querying within a named graph is well expressed in the SPARQL specification [8.2]. In the 4Suite implementation, the name of the current graph is the context's scope. The term scope is used consistently throughout 4Suite to refer to a named graph context associated with an RDF statement, in a manner similar to most RDF data stores (rdflib and Redland, for instance).
Traversal Expressions
The most fundamental kind of expression in Versa is the Traversal Expression. There are three kinds of these:
- Forward Traversal Operators
- Forward Filter Operators
- Backwards Traversal Operators
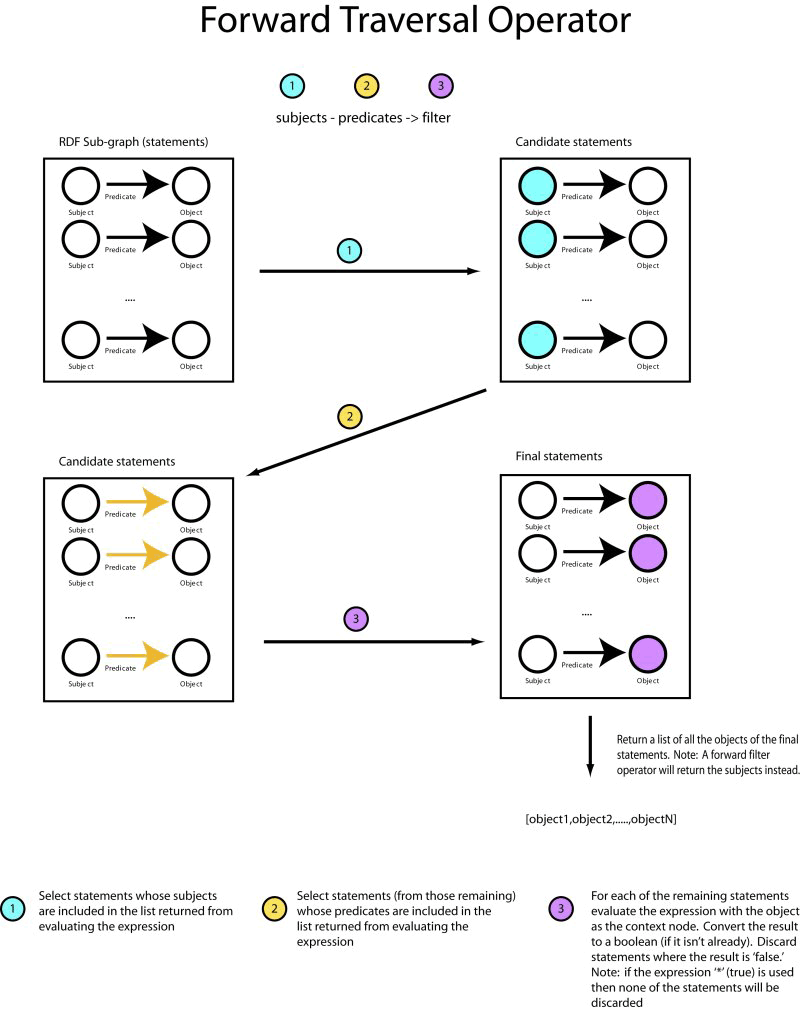
Forward Traversal Operator
A forward traversal operator is an expression that returns a list of objects from statements that match the pattern it represents. Traversal operators are almost direct, visual analogs of SPARQL's basic Triple Patterns [2.2] with Versa expressions at each part, which limits the result set to statements where the corresponding component is a member of a list formed from the result of evaluating the expression. A Versa forward filter operator always takes on the following form:
subjects - predicates -> boolean
The first item (marked subjects above) is evaluated and the result is converted to a list. Statements that match must have a subject whose value is equivalent to any of the resources in the resulting list.
Versa has an explicit set of rules that are followed when converting from one data type to another. This rule matrix is very similar to XPaths. The most common example is to convert a single resource or literal to a list. A resource or literal can be converted to a list by returning a list with the resource or literal as its only member (a list with a length of 1). The complete set of rules is expressed as a matrix in the Versa Specification [3.2].
The second item (marked predicates above) is an expression that is also expected to result in a list of resources. In this case, the expression is evaluated with respect to a list consisting of the resources from the first expression (subjects). Statements that have matched the first criteria (the subjects expression) are examined and excluded if their predicate is not a member of this resulting list.
Finally, the third expression (marked as boolean) is evaluated with respect to the objects of each of the statements that have matched the pattern so far. These expressions are expected to evaluate to a boolean value. If this value is true then the objects of the resulting statements are returned. They are discarded otherwise.
Below is a diagram of this process:
|
|
Consider,
all()-rdfs:label->*
all is a built-in versa function that returns all the resources in the underlying RDF model. The prefix rdfs is always associated with the URI http://www.w3.org/2000/01/rdf-schema#. This URI identifies the domain of concepts that have to do with defining an RDF vocabulary. Within this domain, the property http://www.w3.org/2000/01/rdf-schema#label is defined as:
A human-readable name for the subject.
The example will return the human-readable names of every resource in the underlying RDF model. This is an example of the most common way the "*" character is used.
The SPARQL equivalent would be:
SELECT ?label
WHERE {
?resource rdfs:label ?label
}
Forward Filter Operator
Forward Filter Operators behave the same way as Forward Traversal Operators with the exception that they return the subjects of the candidate statements. They are expressed in the following form:
subjects |- predicates -> boolean
So we could augment the previous query to return all resources that have labels by using a Forward Filter Operator instead:
all()|-rdfs:label->*
In SPARQL:
SELECT ?resource
WHERE {
?resource rdfs:label ?label
}
Backward Traversal Operators
A Backward Traversal Operator essentially expresses the inverse constraint along the same predicate(s). Backward traversal operator expressions are of the form:
object <- predicate - boolean
Below is a more complex example that demonstrates combining traversal expressions in both directions:
(rdfs:Class <- rdf:type - *) - rdfs:comment -> *
This query returns commentary on all classes in the graph and is semantically equivalent to the following SPARQL query:
SELECT ?comment
WHERE {
?class rdfs:comment ?comment.
?class rdf:type rdfs:Class.
}
Variables
Like their XPath counterparts, Versa contexts are associated with a set of variable
bindings. These variables can be referred to by variable references that evaluate
to the
associated data type value.
These are quite different from SPARQL variables. The
latter are Skolem variables which are bound to solutions by the query processor. The
most
common way Versa variables are bound is by an outside process or host language (XSLT,
perhaps) before an expression is evaluated by the query processor. However, it is
not inconceivable to think of such bindings to be created as the result of another
query.
Consider the following sequence:
I.
SELECT ?person
WHERE
{ ?x foaf:name "Chimezie Ogbuji";
rdf:type foaf:Person }
II.
distribute( $person <- foaf:knows - *, '(. - foaf:made -> *) - list(rdfs:label,dc:title) -> *', '. - foaf:name -> *', )
Here we wish to get the label or title of everything made by anyone who knows me as well as the names of these people. We do this with the distribute function (discussed later) and by an interpretation of the way both query languages use variables independently.
Versa Functions
The standard Versa functions include those listed in section [7] of the Versa specification (as well as the functions for converting between data types, listed in section [3.3]). However, we shall focus on four of the more fundamental of these.
Distribute (Data Aggregation)
The distribute function is the most common way data is extracted from targeted resources in the underlying graph. It is also the most difficult to use the first time around because of the format of its result. Below is a diagram of how the distribute function works:

Figure 2. Distribute Execution Diagram
Mathematically, the distribute function is best thought of as the cartesian product (where each pair is the result of applying the expression with the item as the context node) of the list of items in the source list and the list of expressions that follows, grouped in the order of items in the original set.
Type (Class Membership)
The type function returns all members of the given class (or list of classes). At a minimum, it is a short hand for
all()|-rdf:type->member(.,**classes**)
However, the underlying query processor can refer to class membership rules (from a defining OWL/RDFS ontology or schema) in determining its result. 4Suite's implementation follows the rdfs:subClassOf relationships (starting from the given classes) transitively to include members of derived classes (as given by RDFS9).
Properties
The property function returns the names of all relationships going out from (default) or coming in (with vtrav:inverse as the second argument) to the given resource. This is another situation where the query processor could take advantage of other standard RDFS rules.
Imagine you wanted to determine all the possible predicates (properties)—besides rdf:type—that can be expressed on instances of any class. The following are queries written in both SPARQL and Versa for this purpose:
SPARQL
SELECT DISTINCT ?Property
WHERE { ?R rdf:type ?Class .
OPTIONAL { ?R ?Property ?Object .
FILTER ?Property != rdf:type } }
Versa
difference( properties(set(all() |- rdf:type -> *)), set(rdf:type) )
The underlying query processors in both cases can take advantage of RDFS Extensional Entailment Rules or OWL property restrictions (owl:onProperty) to process the request more efficiently and completely.
Filter
The Versa filter function has the same form as distribute, but returns a list comprised of the original items where the result of evaluating every expression as a boolean filter is "true." This kind of filtering is also discussed in [3.2] and [11] of the SPARQL Specification:
Value constraints take the form of boolean-valued expressions; the language also allows application-specific constraints on the values in a query solution.
EVersa?
Query Scoping
The following "extension" functions were added to 4Suite's Versa implementation at a later point in time:
- scoped-subquery()
- scope()
These both have to do with named graphs. The first function (scoped-subquery) takes a string as its first argument and a list of resources or strings as its second argument. The first argument is evaluated as a Versa query with respect to copies of the current context, each of which is associated with graphs named by the second argument as a list. Once again, the most common conversion scenario is going from a string or resource to a list, in which case the result is a list of the string or resource as its only member.
The second function (scope) is very different. It essentially asks the underlying RDF graph to give the scopes (contexts, named graphs) that the given resource (or list of resources) belongs to. More specifically, the scopes of all statements made about the given resource (or resources) are returned. In practice, I've found that the ability to dynamically determine the current context within a traversal and then limit an RDF query to that context is a very common and powerful pattern in RDF query optimization.
Others
Finally, some additional functions can be defined as shorthand for common expressions:
class([member])
as shorthand for:
. - rdf:type -> *
and
member - rdf:type -> *
value([valuedResource])
as shorthand for:
. - rdf:value -> *
and
valuedResource - rdf:value -> *
Splenda for your Versa?
Turtle Constructs
The timing of the advent of SPARQL was such that it could take advantage of a recent RDF serialization syntax that's directly related to Tim Berners-Lee's Notation 3. Unfortunately, Versa was developed during an earlier period where there was no precedent for RDF querying other than RDQL and similar languages.
In the early brainstorming sessions we decided that XPath was the better contemporary for querying RDF data. The result is a very expressive analogy that nevertheless relies quite a bit on functions to perform common operations. Augmenting the syntax with forms that emerged at a later point (Notation 3) would go a long way in alleviating this particular limitation, as well as make Versa even more expressive in general.
I. Versa could easily be extended to work with RDF Literals (and XSD data types) by making use of Notation 3's abbreviated syntax for data types in expressions such as:
all() |- rdf:value -> eq("1.0e6"^^xsd:double)
II. SPARQL's mapping of operator expressions to SPARQL and XPath 2.0 functions (as well as XPath 1.0 boolean expressions) can be adopted as alternatives to:
- lt/lte
- gt/gte
- eq/neq
Like so:
SPARQL
SELECT ?title ?price
WHERE { ?x ns:price ?price .
FILTER ?price < 30 .
?x dc:title ?title . }
Versa
distribute( all() - ns:price -> < "30", 'dc:title', '. - ns:price -> *', )
or
[ - ns:price -> < "30"] - list(dc:title ns:price) -> *
III. This latter form makes use of Notation 3's [ .. ] to represent traversal expressions evaluated against blank nodes as existential placeholders or wildcards. The term [ - predicates -> objects] would be shorthand for (all() |- predicates -> objects).
Versa originally used "[" and "]" as predicate filters (in the same way that XPath does), but this didn't make it to the final specification. Given the nature of blank nodes (as placeholders for statements made about resources where the identity is unimportant), Notation 3's use of the same form seems preferable.
IV. Finally, Python list iteration and indexing operators (such as in [:3], [1:3], and [:-4]) can be adopted as alternatives to: member, item, rest, tail, and slice.
Consider the following query that returns the title of the most recent rss:item in a feed:
sortq(type(rss:item),'. - dc:date-> *')[-1] - rss:title -> *
This would conflict with the earlier suggested use of "[". A different set of bracketing characters could be used for either instead: "{" and "}" perhaps.
Revisiting Syntax in the Semantic Web Stack
The success of the Semantic Web initiative is very heavily dependent on the ubiquitous adoption of its various syntaxes. These fall into the following groups:
- Rules (OWL,RDFS,SWRL,N3,etc.)
- Query (SPARQL,Versa,etc.)
- Knowledge Representation (RDF/XML,N3)
This can be seen as a bottom-up stack with components in common with traditional Expert Systems. The lower end of this stack (knowledge representation in particular) is the more matured level (in both Semantic Technologies and Expert Systems). The adoption of Notation 3 syntax (and other subsets of Notation 3) into the more recent RDF standards is evidence of this. The middle portion of the stack is where the focus has recently shifted, and the rich spectrum of graph traversal syntaxes (spanning between Versa and SPARQL) stands poised to move the initiative to the next step and towards the final goal: what essentially amounts to the framework for a massively distributed expert system.
Resources
|