The Evolution of JAXP
July 6, 2005
Introduction
After the first release of the W3C XML 1.0 recommendation in early 1998, XML started gaining huge popularity. Sun Microsystems Inc., at that time had just formalized the Java Community Process (JCP), and the first version of JAXP (JSR-05) was made public in early 2000, supported by industry majors like (in chronological order) BEA Systems, Fujitsu Limited, Hewlett-Packard, IBM, Netscape Communications, Oracle, and Sun Microsystems, Inc.
JAXP 1.0, then called Java API for XML Parsing, was a box office hit in the developer community, because of the pluggability layer provided by JAXP; that's what the essence of JAXP is. Developers can write program independent of the underlying XML processor by using the JAXP APIs, and can replace the underlying XML processor by choice without even changing a single line of application code.
So what exactly is JAXP? First of all, there has been some confusion in the past about the P in JAXP: Parsing or Processing? Because JAXP 1.0 supported only parsing, therefore, it was called Java API for XML Parsing. But in JAXP 1.1 (JSR-63), XML transformation was introduced using XSL-T. Unfortunately, the W3C XSL-T specification does not provide any APIs for transformation. Therefore, the JAXP 1.1 Expert Group (EG) introduced a set of APIs called Transformation API for XML (TrAX) in JAXP 1.1, and since then, JAXP is called Java API for XML Processing. Thereafter, JAXP has evolved to an extent, where now it supports a lot more things (like validation against schema while parsing, validation against preparsed schema, evaluating XPath expressions, etc.,) than only parsing an XML document.
So, JAXP is a lightweight API to process XML documents by being agnostic of the underlying XML processor, which are pluggable.
XML Parsing Using JAXP
JAXP supports Object-based and Event-based parsing. In Object-based, only W3C DOM parsing is supported so far. Maybe in future versions of JAXP, the EG might decide to support J-DOM as well. In Event-based, only SAX parsing is supported. Another Event-based parsing called Pull Parsing, should have been made part of JAXP. But, there is a different JSR (#173) filed for pull parsing, also known as Streaming API for XML (StAX) parsing, and nothing much can be done about that now.
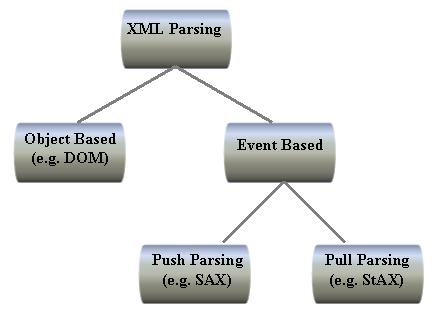
Figure 1: Various mechanism of parsing XML.
Simple API for XML (SAX) Parsing
SAX APIs were proposed by David Megginson (in early 1998) as an effort towards a standard API for event-based parsing of XML (read the genesis of SAX here). Even though SAX is not a W3C REC, it is surely the de facto industry standard for parsing XML documents.
SAX parsing is an event-based, push-parsing mechanism, which generates events for the <opening> tags, </closing> tags, the character data, and so on. A SAX parser parses an XML document in a streaming fashion (forward only) and reports the events, in the sequence encountered, to the registered content handler, org.xml.sax.ContentHandler, (Don't get confused with the java.net.ContentHandler.) and errors (if any) to the registered error handler, org.xml.sax.ErrorHandler.
If you don't register an error handler, you will never know if there was any error while parsing the XML, and what it was. Therefore, it becomes extremely important to always register a meaningful error handler while SAX parsing an XML document.
If the application needs to be informed of the parsing events (and process it), it must implement the org.xml.sax.ContentHandler interface and register it with the SAX parser. A typical sequence of events reported through the callbacks could be startDocument, startElement, characters, endElement, endDocument, in that order. startDocument is called only once before reporting any other event. Similarly, endDocument is called only once after the entire XML is parsed successfully. See the javadocs for more details.

Figure 2: SAX Parsing XML
Snippet to SAX parse an XML document using JAXP:
SAXParserFactory spfactory = SAXParserFactory.newInstance();
spfactory.setNamespaceAware(true);
SAXParser saxparser = spfactory.newSAXParser();
//write your handler for processing events and handling error
DefaultHandler handler = new MyHandler();
//parse the XML and report events and errors (if any) to the handler
saxparser.parse(new File("data.xml"), handler);
Document Object Model (DOM) Parsing
DOM parsing is an object-based parsing mechanism, which generates an XML object model: an inverted tree-like data structure, which represents the XML document. Every element node in the object model represents a pair of <opening> and </closing> tags in the XML. A DOM parser reads the entire XML file and creates an in-memory data structure called DOM. If the DOM parser is W3C compliant, then, the DOM created is a W3C DOM, which can be traversed or modified using the org.w3c.dom APIs.
Most of the DOM parsers also allow you to create an in-memory DOM structure from scratch, rather than just parsing an XML to a DOM.

Figure 3: DOM Parsing XML
Snippet to DOM parse an XML document using JAXP:
DocumentBuilderFactory dbfactory = DocumentBuilderFactory.newInstance();
dbfactory.setNamespaceAware(true);
DocumentBuilder domparser = dbfactory.newDocumentBuilder();
//parse the XML and create the DOM
Document doc = domparser.parse(new File("data.xml"));
//to create a new DOM from scratch -
//Document doc = domparser.newDocument();
//once you have the Document handle, then you can use
//the org.w3c.dom.* APIs to traverse or modify the DOM...
Parsing in Validating Mode
Validation Against DTD
DTD is a grammar for XML documents. Often people think that DTD is something alien because it has a different syntax than XML, but DTD is an integral part of W3C XML 1.0. If an XML instance document has a DOCTYPE declaration, then to turn on validation against DTD, while parsing XML, you need to set the validating feature to true using the setValidating method on the appropriate factory. For example:
DocumentBuilderFactory dbfactory = DocumentBuilderFactory.newInstance();
dbfactory.setValidating(true);
OR
SAXParserFactory spfactory = SAXParserFactory.newInstance();
spfactory.setValidating(true);
Note that, even if the validation is turned off, and if the XML instance has a DOCTYPE declaration to an external DTD, the parser always tries to load that DTD. This is done to ensure that any entity references in the XML instance (entity declarations being in the DTD) are expanded properly, which otherwise might lead to a malformed XML document, until and unless the standalone attribute on the XML declaration prolog is set to true, in which case the external DTD is ignored completely. For example:
<?xml version="1.1" encoding="UTF-8" standalone="yes"?>
Validation Against W3C XMLSchema (WXS)
XMLSchema is yet another grammar for XML documents, and has gained huge popularity because of the XML syntax it uses, and the richness it provides to define fine grained validation constraints. If an XML instance document points to XMLSchema using the "schemaLocation" and "noNamespaceSchemaLocation" hints, then to turn on validation against XMLSchema, you need to do the following things:
- Set the validating feature to true using the setValidating method on SAXParserFactory or DocumentBuilderFactory, as mentioned above.
- Set the property "http://java.sun.com/xml/jaxp/properties/schemaLanguage" with the corresponding value as "http://www.w3.org/2001/XMLSchema"
Note that, in this case, even if a DOCTYPE exists in the XML instance, the instance won't be validated against DTD. But as mentioned earlier, surely it would be loaded so that any entity references can be expanded properly.
Since "schemaLocation" and "noNamespaceSchemaLocation" are just hints, the schemas can also be provided externally to override these hints, using the property "http://java.sun.com/xml/jaxp/properties/schemaSource". The acceptable value for this property must be one of the following:
- java.lang.String that points to the URI of the schema
- java.io.InputStream with the contents of the schema
- org.xml.sax.InputSource
- java.io.File
- an array of java.lang.Object with the contents being one of the types defined above.
For example:
SAXParserFactory spfactory = SAXParserFactory.newInstance();
spfactory.setNamespaceAware(true);
//turn the validation on
spfactory.setValidating(true);
//set the validation to be against WXS
saxparser.setProperty("http://java.sun.com/xml/jaxp/properties/
schemaLanguage", "http://www.w3.org/2001/XMLSchema");
//set the schema against which the validation is to be done
saxparser.setProperty("http://java.sun.com/xml/jaxp/properties/
schemaSource", new File("myschema.xsd"));
XML Transformation Using the TrAX APIs in JAXP
W3C XSL-T defines transformation rules to transform a source tree into a result tree. A transformation expressed in XSL-T is called a stylesheet. To transform an XML document using JAXP, you need to create a Transformer using the stylesheet. Once a Transformer is created, it takes the XML input to be transformed as a JAXP Source, and returns the transformed result as a JAXP Result. There are three types of sources and results that JAXP provides: StreamSource, SAXSource, DOMSource and StreamResult, SAXResult, DOMResult, which can be used in any combination for transformation.

Figure: XML Transformation
For example, to generate SAX events from DOM:
//parse the XML file to a W3C DOM
DocumentBuilderFactory dbfactory = DocumentBuilderFactory.newInstance();
dbfactory.setNamespaceAware(true);
DocumentBuilder domparser = dbfactory.newDocumentBuilder();
Document doc = domparser.parse(new File("data.xml"));
//prepare the DOM source
Source xmlsource = new DOMSource(doc);
//create a content handler to handle the SAX events
ContentHandler handler = new MyHandler();
//prepare a SAX result using the content handler
Result result = new SAXResult(handler);
//create a transformer factory
TransformerFactory xfactory = TransformerFactory.newInstance();
//create a transformer
Transformer xformer = xfactory.newTransformer();
//transform to raise the SAX events from DOM
xformer.transform(xmlsource, result);
In the above example, we haven't used any XSL while creating the Transformer. This means the Transformer would merely pour the XML from the Source to the Result without any transformation. When you want to actually transform using a XSL, then you should create the Transformer using the XSL source as follows:
//create the xsl source
Source xslsource = new StreamSource(new File("mystyle.xsl"));
//create the transformer using the xsl source
Transformer xformer = xfactory.newTransformer(xslsource);
What's New in JAXP 1.3
Apart from supporting SAX parsing, DOM parsing, validation against DTD/XMLSchema while parsing, transformation using XSL-T, from the previous versions, JAXP 1.3 additionally supports:
- XML 1.1 and Namespaces in XML 1.1
- XML Inclusions - XInclude 1.0
- Validation of instance against preparsed schema (XMLSchema and RELAX-NG).
- Evaluating XPath expressions.
- XML/Java type mappings for those datatypes in XMLSchema 1.0, XPath 2.0 and XQuery 1.0 for which there wasn't any XML/Java mappings earlier.
Using JAXP 1.3
XML 1.1 and XInclude 1.0
Major things supported in XML 1.1 are:
- forward compatibility for the ever-growing Unicode character set.
- addition of NEL (#x85) and the Unicode line separator character (#x2028) to the list of line-end characters.
Changes in XML 1.1 are not fully backward compatible with XML 1.0 and also break the well-formedness rules defined in XML 1.0. Therefore, a new specification, XML 1.1, was proposed rather than simply updating the existing XML 1.0 specification.
To use XML 1.1 and the Namespaces in XML 1.1 feature, you must set the value of the version attribute, in the XML declaration prolog, of your XML document, to "1.1." For example:
<?xml version="1.1" encoding="UTF-8" standalone="yes"?>
XInclude allows an XML document to include other XML documents. For example:
<myMainXMLDoc xmlns:xi="http://www.w3.org/2001/XInclude">
<xi:include href="fragment.xml"/>
...
</myMainXMLDoc>
To allow XML inclusions, you must set the XInclude feature on the appropriate factory as follows:
DocumentBuilderFactory dbfactory = DocumentBuilderFactory.newInstance();
dbfactory.setXIncludeAware(true);
Validating a JAXP Source Against a Preparsed Schema
javax.xml.validation package provides support for parsing a schema, and validating XML instance documents against those preparsed schemas. A JAXP DOMSource or a SAXSource can be validated against a preparsed schema. The preparsed schema can be cached for optimization, if required. Note that the JAXP StreamSource is not supported and that the schema can be either a W3C XML Schema or an OASIS RELAX-NG. For example:
//parse an XML in non-validating mode and create a DOMSource
DocumentBuilderFactory dbfactory = DocumentBuilderFactory.newInstance();
dbfactory.setNamespaceAware(true);
dbfactory.setXIncludeAware(true);
DocumentBuilder parser = dbfactory.newDocumentBuilder();
Document doc = parser.parse(new File("data.xml"));
DOMSource xmlsource = new DOMSource(doc);
//create a SchemaFactory for loading W3C XML Schemas
SchemaFactory wxsfactory =
SchemaFactory.newInstance(XMLConstants.W3C_XML_SCHEMA_NS_URI);
//set the errorhandler for handling errors in schema itself
wxsfactory.setErrorHandler(schemaErrorHandler);
//load a W3C XML Schema
Schema schema = wxsfactory.newSchema(new File("myschema.xsd"));
// create a validator from the loaded schema
Validator validator = schema.newValidator();
//set the errorhandler for handling validation errors
validator.setErrorHandler(validationErrorHandler);
//validate the XML instance
validator.validate(xmlsource);
Evaluating XPath Expressions
javax.xml.xpath package provides support for executing XPath expressions against a given XML document. The XPath expressions can be compiled for performance reasons, if it is to be reused.
By the way, the XPath APIs in JAXP are designed to be stateless, which means every time you want to evaluate an XPath expression, you also need to pass in the XML document. Often, many XPath expressions are evaluated against a single XML document. In such a case, it would have been better if the XPath APIs in JAXP were made stateful by passing the XML document once. The underlying implementation would then have had a choice of storing the XML source in an optimized fashion (say, a DTM) for faster evaluation of XPath expressions.
An example to evaluate the XPath expressions against the following XML document:
<?xml version="1.0"?>
<employees>
<employee>
<name>e1</name>
</employee>
<employee>
<name>e2</name>
</employee>
</employees>
//parse an XML to get a DOM to query
DocumentBuilderFactory dbfactory = DocumentBuilderFactory.newInstance();
dbfactory.setNamespaceAware(true);
dbfactory.setXIncludeAware(true);
DocumentBuilder parser = dbfactory.newDocumentBuilder();
Document doc = parser.parse(new File("data.xml"));
//get an XPath processor
XPathFactory xpfactory = XPathFactory.newInstance();
XPath xpathprocessor = xpfactory.newXPath();
//set the namespace context for resolving prefixes of the Qnames
//to NS URI, if the xpath expresion uses Qnames. XPath expression
//would use Qnames if the XML document uses namespaces.
//xpathprocessor.setNamespaceContext(NamespaceContext nsContext);
//create XPath expressions
String xpath1 = "/employees/employee";
XPathExpression employeesXPath = xpathprocessor.compile(xpath1);
String xpath2 = "/employees/employee[1]";
XPathExpression employeeXPath = xpathprocessor.compile(xpath2);
String xpath3 = "/employees/employee[1]/name";
XPathExpression empnameXPath = xpathprocessor.compile(xpath3);
//execute the XPath expressions
System.out.println("XPath1="+xpath1);
NodeList employees = (NodeList)employeesXPath.evaluate(doc,
XPathConstants.NODESET);
for (int i=0; i<employees.getLength(); i++) {
System.out.println(employees.item(i).getTextContent());
}
System.out.println("XPath2="+xpath2);
Node employee = (Node)employeeXPath.evaluate(doc, XPathConstants.NODE);
System.out.println(employee.getTextContent());
System.out.println("XPath3="+xpath3);
String empname = empnameXPath.evaluate(doc);
System.out.println(empname);
XML/Java-type Mappings
Datatypes in XMLSchema 1.0 are quite exhaustive and popular, and are used by many other XML specifications as well, like XPath, XQuery, WSDL, etc... Most of these datatypes naturally map to the primitive or wrapper datatypes in Java. The rest of the datatypes like dateTime, duration, etc., can be mapped to the new Java types: javax.xml.datatype.XMLGregorianCalendar, javax.xml.datatype.Duration, and javax.xml.namespace.QName. Thus, along with the new datatypes defined in javax.xml.datatype package, all the datatypes supported in XMLSchema 1.0, XPath 2.0 and XQuery 1.0 now have an equivalent datatype mapping in Java.
But, the datatype support would have been much better from a usability perspective if the DatatypeFactory had methods to get a Java object for the given WXS datatype, which has methods to constrain the datatypes using facets, and validate a value against the datatype.
An example using Oracle's XDK:
import oracle.xml.parser.schema.*;
. . .
//create a simpleType object
XSDSimpleType st = XSDSimpleType.getPrimitiveType(XSDSimpleType.iSTRING);
//set a constraining facet on the simpleType
st.setFacet(XSDSimpleType.LENGTH, "5");
//validate value
st.validateValue("hello");
Changing the Underlying Implementation
A JAXP implementation comes with a default parser, transformer, xpath engine, and a schema validator, but, as mentioned earlier, JAXP is a pluggable API, and we can plug in any JAXP complaint processor to change the defaults. To do that we must set the appropriate javax.xml.xxx.yyyFactory property pointing to the fully qualified class name of the new yyyFactory. Then, when yyyFactory.newInstance() is invoked, JAXP uses the following ordered lookup procedure to determine the implementation class to load:
- Use the javax.xml.xxx.yyyFactory system property.
- Use the properties file "lib/jaxp.properties" in the JRE directory. The jaxp.properties file is read only once by the JAXP 1.3 implementation and its values are then cached for future use. If the file does not exist when the first attempt is made to read from it, no further attempts are made to check for its existence. It is not possible to change the value of any property in jaxp.properties after it has been read for the first time.
- Use the Services API (as detailed in the JAR specification), if available, to determine the classname. The Services API will look for the classname in the file META-INF/services/javax.xml.xxx.yyyFactory in jars available to the runtime.
- Use the platform default javax.xml.xxx.yyyFactory instance
where javax.xml.xxx.yyyFactory can be one of the following:
javax.xml.parsers.SAXParserFactory
javax.xml.parsers.DocumentBuilderFactory
javax.xml.transform.TransformerFactory
javax.xml.xpath.XPathFactory
javax.xml.validation.SchemaFactory:schemaLanguage (schemaLanguage is the
parameter passed to the newInstance method of SchemaFactory)
For example, to plug in a JAXP complaint SAX parser, say Apache's Xerces, you must set the property javax.xml.parsers.SAXParserFactory to org.apache.xerces.jaxp.SAXParserFactoryImpl, in any of the four ways mentioned above. One of the ways is shown below:
java -Djavax.xml.parsers.SAXParserFactory=
org.apache.xerces.jaxp.SAXParserFactoryImpl MyApplicationProgram