Multimodal Interaction on the Web
January 21, 2004
Introduction
The W3C Multimodal Interaction Activity is developing specifications as a basis for a new breed of Web application with multiple modes of interaction. Consider applications which use speech, hand writing, and key presses for input, and spoken prompts, audio and visual displays for output. It is implemented by several drafts, which we will briefly review in this article. These include InkML, a language that serves as the data exchange format for representing ink entered with an electronic pen or stylus; and EMMA, a data exchange format for representing application specific interpretations of user input together with annotations such as confidence scores, time stamps, and input medium.
Multimodal interactions are the center of multimodal systems, systems that support communication with the user through different modes, including voice, gesture, handwriting, and typing. In multimodal systems an event is a representation of some occurrence of interest to the multimodal system. Examples include mouse clicks, hanging up the phone, speech recognition results or errors. Events may be associated with information about the user interaction e.g. the location the mouse was clicked.
Interaction (input, output) between the user and the application may often be conceptualized as a series of dialogs, managed by an interaction manager. A dialog is an interaction between the user and the application that involves turn-taking. In each turn, the interaction manager manager working on behalf of the application collects input from the user, processes it using the session context and possibly external knowledge sources, computes a response and updates the presentation for the user.
The field of potential use cases of multimodal interaction is very broad. Devices deployed in different use cases can be classified from the point of view of "thickness": a thin client is a device with little processing power and capabilities that can be used to capture user input (microphone, touch display, stylus, etc.) as well as non-user input such as GPS; a thick client such as PDA or notebook; and a medium client: a device capable of input capture and some degree of interpretation. Processing is distributed in a client-server or a multidevice architecture. You can view several use cases for multimodal interaction in a special W3C Note about Multimodal Interaction Use Cases.
Interaction Framework
The W3C Multimodal Interaction Framework describes input and output modes widely used today and can be extended to include additional modes of user input and output as they become available. The framework identifies the major components for every multimodal system. Each component represents a set of related functions. The framework identifies the markup languages used to describe information required by components and for data flowing among components. The Framework will build upon a range of existing W3C markup languages together with the W3C DOM. DOM defines interfaces whereby programs and scripts can dynamically access and update the content, structure, and style of documents. The basic components of a framework are illustrated in Figure 1.
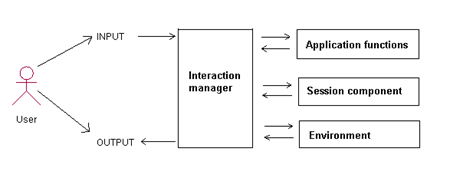
Figure 1. Basic components of the Multimodal Interaction Framework
In Figure 1, the Human user enters input into the system, and the user also observes and hears information presented by the system. The interaction manager is the logical component that coordinates data and manages execution flow from various input and output modality component interface objects. It maintains the interaction state and context of the application and responds to inputs from component interface objects and changes in the system and environment. It then manages these changes and coordinates input and output across component interface objects.
The Session component provides an interface to the interaction manager to support state management and temporary and persistent sessions for multimodal applications. The Environment component enables the interaction manager to find out about and respond to changes in device capabilities, user preferences, and environmental conditions. For example "in which of the available modes that the user wishes to use have they muted audio input?" Each of these components can be broked down futher, though such details are out of the scope of this article.
Markup Languages
There are currently two specifications of XML-based markup languages for use within multimodal interaction framework: EMMA and InkML. I'll briefly review both.
InkML
As more electronic devices with pen interfaces become available for entering and manipulating information, applications need to be more effective at leveraging this method of input. Handwriting is an input mode that is very familiar for most users. Users will tend to use this as a mode of input and control when available. Hardware and software vendors have typically stored and represented digital ink using proprietary or restricted formats. The lack of a public and comprehensive digital ink format has severely limited the capture, transmission, processing, and presentation of digital ink across heterogeneous devices developed by multiple vendors. In response to this need, the Ink Markup Language (InkML) provides a simple and platform-neutral data format to promote the interchange of digital ink between software applications.
With the establishment of a non-proprietary ink standard, a number of applications, old and new, will be able to use the pen as a very convenient and natural form of input. The current InkML specification defines a set of primitive elements sufficient for all basic ink applications. Few semantics are attached to these elements. All content of an InkML document is contained within a single <ink> element. The fundamental data element in an InkML file is the <trace>. A trace represents a sequence of contiguous ink points -- e.g., the X and Y coordinates of the pen's position. A sequence of traces accumulates to meaningful units, such as characters and words. The <traceFormat> element is used to define the format of data within a trace.
Ink traces can have certain attributes such as color and width. These attributes are captured in the <brush> element. Traces that share the same characteristics, such as being written with the same brush, can be grouped together with the <traceGroup> element. In the simplest form, an InkML instance looks like this:
<ink>
<trace>
10 0 9 14 8 28 7 42 6 56 6 70 8 84 8 98 8 112 9 126 10 140
13 154 14 168 17 182 18 188 23 174 30 160 38 147 49 135
58 124 72 121 77 135 80 149 82 163 84 177 87 191 93 205
</trace>
<trace>
130 155 144 159 158 160 170 154 179 143 179 129 166 125
152 128 140 136 131 149 126 163 124 177 128 190 137 200
150 208 163 210 178 208 192 201 205 192 214 180
</trace>
<trace>
227 50 226 64 225 78 227 92 228 106 228 120 229 134
230 148 234 162 235 176 238 190 241 204
</trace>
<trace>
282 45 281 59 284 73 285 87 287 101 288 115 290 129
291 143 294 157 294 171 294 185 296 199 300 213
</trace>
<trace>
366 130 359 143 354 157 349 171 352 185 359 197
371 204 385 205 398 202 408 191 413 177 413 163
405 150 392 143 378 141 365 150
</trace>
</ink>
This is the trace for user input of Hello word, shown in Figure 2.

Figure 2. Graphical
pen input with marked trace points
InkML is rich and simple language, you can see it more detailed at W3C InkML current Draft page.
EMMA
EMMA is the Extensible MultiModal Annotation markup language. It is intended for use by systems that provide semantic interpretations for a variety of inputs, including but not necessarily limited to speech, natural language text, GUI, and ink input. The language is focused on annotating the interpretation information of single and composed inputs, as opposed to (possibly identical) information that might have been collected over the course of a dialog, providing a set of elements and attributes that are focused on accurately representing annotations on the input interpretations.
An EMMA document typically contains three parts:
- Instance data: application-specific markup corresponding to input information which is meaningful to the consumer of an EMMA document. Instances are application-specific and built by input processors at runtime. Given that utterances may be ambiguous with respect to input values, an EMMA document may hold more than one instance.
- Data model: constraints on structure and content of an instance.
- Metadata: used as annotations associated with the data contained in the instance. Annotation values are added by input processors at runtime.
The Multimodal Interaction Working Group is currently considering the role of RDF in EMMA syntax and processing. It appears useful for EMMA to adopt the RDF graph model, and thereby enable RDF processing in RDF environments. However, there is concern that unnecessary processing overhead will be introduced by a requirement for all EMMA environments to support the RDF syntax and its related constructs. An inline XML syntax would remove this requirement, provide a more compact representation, and enable queries on annotations using XPath, just as for queries on instance data. For these reasons, currently there are three syntax proposals: inline XML syntax, an RDF/XML syntax, and a mixed inline+RDF syntax. You can see the detailed description of RDF (Resource Description Framework) at the W3C's RDF page.
The general purpose of EMMA is to represent information automatically extracted from a user's input by an interpretation component, where input is to be taken in the general sense of a meaningful user input in any modality supported by the platform. In the architecture shown in Figure 1 EMMA conveys content between user input components and an interaction manager.
Components that generate EMMA markup include speech recognizers, handwriting recognizers, natural language processing engines, DTMF signals, keyboard, pointing devices such as mouse, multimodal integration component. Components that use EMMA include the interaction manager and multimodal integration component.
EMMA is still under development, but it has a large potential for integrating different devices on the Web. More than that, it can make a Web accessible in its full sense for future applications. There should be no difference in interacting with a user via phone DTMF tones, PDA ink pens, or even voice browsers for users with disabilities. This is an impressive goal, and the Multimodal Interaction Framework is a next step in achieving it.