XSLT Processor Benchmarks
March 28, 2001
Eugene Kuznetsov and Cyrus Dolph
Overview
| Table of Contents |
|
•XML performance and
XSLT |
XSLTMark is a benchmark for the comprehensive measurement of XSLT processor performance. It consists of forty test cases designed to assess important functional areas of an XSLT processor. The latest release, version 2.0, has been used to assess ten different processors. This article describes the benchmark methodology and provides a brief overview of the results.
Important Update (2001/04/04). Since the first publication of this article, errors in the methodology has been discovered. Although this doesn't affect the "headline news," it is significant. For full details please be sure to read the complete explanation below in the "Results" section. The performance chart has been updated to reflect the corrections.
XML performance and XSLT
The performance of XML processing in general is of considerable concern to both customers and engineers alike. With more and more XML-encoded data being transmitted and processed, the ability to both predict and improve XML performance is critical to delivering scalable and reliable solutions. While XSLT is a big part of delivering on the overall value proposition of XML (by allowing XML-XML data interchange and XML-HTML content presentation), it also presents the greatest performance challenge. Early anecdotal evidence showed wide disparities in real-life results, and no comprehensive benchmark tools were available to obtain more systematic assessments and comparisons. We first created and started using XSLTMark internally at DataPower in mid-2000 and released it publicly in November. By using a well-balanced test base it is possible to make predictions about likely application behavior and to select the best processor for a given application. Considerable improvements have been made by some XSLT engines over the past six months, but it is also clear that further performance improvements will be required to support the growth of XML.
Scoring System
We considered many possible scoring systems for measuring XSLT performance. A survey of existing non-XML benchmark platforms revealed that many benchmarks use abstract unit-less scores to rate performance. These scores are often composed of weighted averages of separate benchmark components that would not be otherwise aggregated. While the abstract scoring method is excellent for relative studies of performance, it lacks the value of a "real-world" number in a standard unit.
Most of the other efforts to assess XSLT performance have centered around execution time measurements for a small number of test cases (where lower scores are better). These numbers are again great for relative comparison, but they are hard to assess in an absolute sense (i.e., in relation to other types of computer processing).
For these reasons, and because XML is increasingly becoming part of the network, XSLTMark uses kilobytes-per-second as its overall score, where kilobytes are the average of input and output document size. This provides a score that is tied to both the document size and the time expended for processing. The variations between scores for different test cases are then attributable to the complexity and specifics of processing performed by the stylesheet and the structure of the input document. By examining the detailed data for the individual cases a great deal of additional knowledge can be gleaned. We conducted some preliminary tests to obtain nodes-per-second measurements, but in the end we settled on kilobytes-per-second as the best way to characterize real-world performance.
The first two releases of XSLTMark computed as a total score an aggregate KB/s measurement, computed according to the total execution time and total kilobytes processed. We like this calculation because it strictly measures the overall performance of the processor on a very broad range of tasks. It is important to understand that this aggregate score gives more weight to computationally-intensive test cases -- since the score is based on the total execution time, the "slower" test cases will have a greater effect on the score. This contrasts with an arithmetic mean of individual test case scores, which is weighted in favor of "faster" test cases.
XSLTMark 2.0 introduces a geometric mean score in addition to the aggregate score. We include this measurement because it provides an average of test case scores in a manner that is not weighted by the qualities of individual test cases. Specifically, scaling the throughput of a single test case results in a scaling of the geometric mean by a factor that does not depend on which test case is scaled.
In order to support both C/C++ and Java processors, XSLTMark uses wall clock time (elapsed real world time, rather than CPU seconds) as obtained by gettimeofday() or Java's System.currentTimeMillis(). This means that benchmarking must occur on an unloaded system, and tests should execute a sufficient number of iterations to avoid real time clock granularity and interrupt effects. Considerable time was invested in ensuring that this approach produced precise and accurate measurements.
Result Verification
The spotty compliance of many XSLT processors meant that we had to spend considerable time manually verifying the output of various tests. DataPower's internal projects also required that results be verified, so basic compliance checking was built into XSLTMark early on. The intent is not to provide a compliance test suite; although XSLTMark is comprehensive in its functional area coverage and presents a balanced performance assessment, it is not comprehensive enough for a full compliance suite. We look forward to the compliance efforts of OASIS and W3C. XSLTMark's compliance testing exists to ensure that largely incomplete processors do not receive unfairly high benchmarks. This is especially important because implementing many parts of the XSLT specification correctly means a certain performance penalty. Often a processor that does well on a subset of cases but fails many others will be considerably slower by the time it achieves full compliance. (This was the case for Transformiix, Mozilla's XSLT processor, which has made great progress in compliance but at a cost to performance).
Result verification is achieved by normalizing the output using DataPower's "dgnorm" (for "normalizer") tool. This simple C program is a SAX processor that removes insignificant whitespace, handles HTML peculiarities, alphabetically sorts attributes and does some other processing to make the output of XSLTMark stylesheets directly accessible to "diff" and byte-wise compares. After normalization, a simple comparison of a reference result and the output is performed. (Purists correctly protest that dgnorm is not a general XML normalizer; it is only suitable for normalizing the results of XSLTMark testcases).
It should be noted that sometimes there's more than one correct result, in which case it's still necessary to verify all "CHK OUTPUT" lines to make sure that they reflect a real compliance problem. This is why some benchmark results have a few manually corrected scores. Previous XSLTMark releases triggered comments from a number of prominent XSLT implementers, and some of the thorny compliance ambiguities have been resolved in the current version. The number test case was difficult to assess due to ambiguity in the XSLT specification and widespread disagreement among processors, so we omitted the associated reference file; hence the "NO REFERENCE" found in the detailed results.
The Tests
The two main kinds of XSL application are XML to HTML and XML to XML conversion. These have different performance profiles, so both types of tests are included in XSLTMark. Real-life use cases range from simply filling in an almost static HTML template to complex processing or conversion of business documents. The four major components of XSLT processing are
- XSLT template pattern matching and template instantiation
- XSLT control structures and parameter passing
- XPath selection of nodesets and predicates
- XPath library functions such as string and nodeset operations
XSLTMark test cases assess the performance of processors in all four of these areas, and Table 1 gives a breakdown of test cases versus XSLT components. Some test cases attempt to isolate specific processing phases (which is not always possible), while others are balanced and therefore more realistic. The performance of the output phase of the processing is also very important, especially when the processing itself is highly optimized.
Table 1: The Test Cases
| Test Case | Input Size | Input Description | Stylesheet | Notes |
| alphabetize | M | 100-row database table | select, control | Sorts the input tree according to element name. |
| attsets | S | sales report | general | Tests node-copying using named attribute sets. |
| avts | M | 100-row database table | select | Tests attribute-value template expansion. |
| axis | S | select | Tests XPath selection along the different axes. | |
| backwards | S | control | Reverses order of elements in input document. | |
| bottles | S | initial size parameter | function, control | Generates "99 bottles of beer on the wall" song. |
| breadth | S | broad and shallow tree | select, control | Performs a search for a unique element in a large tree. |
| brutal | S | select, function, control | Executes many functions, sorts, etc. | |
| chart | S | sales report | select, control | Generates an HTML chart of some sales data. |
| creation | M | 100-row database table | general | Tests xsl:element and xsl:attribute. |
| current | S | select | Tests complex XPath node selection. | |
| dbonerow | L | 10000-row database table | select, control | Selects a single row from a very large table. |
| dbtail | M | 100-row database table | select | Prints a table by traversing the following-sibling axis. |
| decoy | S | 100-row database table | match | Same template as patterns, with some decoy templates thrown in. |
| depth | S | narrow and deep tree | select, control | Performs a search for a unique element in a large tree. |
| encrypt | M | 100-row database table | function | Performs a Rot-13 operation on all element names and text nodes |
| functions | M | 100-row database table | function | Tests a variety of number and string functions. |
| game | S | baseball game stats | select, functions, control | Produces a HTML table of the data. |
| html | S | select, control | Literal result element as stylesheet example from XSLT spec. | |
| identity | L | 1000-row database table | control | The identity transform. |
| inventory | S | Inventory data | select, control | Produces a HTML table of the data. |
| metric | S | Data in metric notation | function | Converts metric units to English units. |
| number | S | function | Tests format-number() function. | |
| oddtemplate | S | match, select | Tests a variety of complex match patterns. | |
| patterns | M | 100-row database table | match | Stylesheet contains extremely simple templates with tough patterns. |
| prettyprint | M | 100-row database table | control, function | Formats the input input legal HTML. |
| priority | S | select, control | Pops the first element off a priority Queue and returns the queue. | |
| products | S | Product data | select, control | Produces an HTML table from the data. |
| queens | S | initial size parameter | function, control | Solves the "8 Queens" problem. (Stylesheet by Oren Ben-Kiki, used with permission.) |
| reverser | S | The Gettysburg Address | function, control | Stylesheet copies input with text-node strings reversed. |
| stringsort | L | 1000-row database table | control | Performs a sort based on string keys. |
| summarize | S | "Queens" stylesheet | function | Reports information about an XSL stylesheet. |
| total | S | sales report | select, function | Reports on sales data. |
| tower | S | initial size parameter | control, function | Solves the Towers of Hanoi problem. |
| trend | S | Numerical data | select, functions | Computes trends in the input data. |
| union | S | match, select | Performs complex pattern matching. | |
| xpath | S | match | Performs complex pattern matching. | |
| xslbench1 | S | test1.xml from XSLBench | general | This test case is "test1.xsl" from Kevin Jones' XSLBench test suite, used with permission. |
| xslbench2 | L | A Midsummer Night's Dream | match, select | This test case is "test2.xsl" from Kevin Jones' XSLBench test suite, used with permission. |
| xslbench3 | L | A Midsummer Night's Dream | select, function | This test case is "test3.xsl" from Kevin Jones' XSLBench test suite, used with permission. |
Results
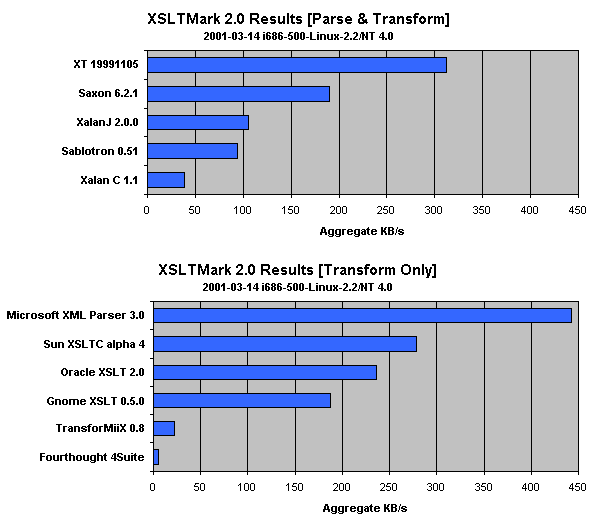
Of the processors included in this release of the benchmark, MSXML, Microsoft's C/C++ implementation, is the fastest overall. The three leading Java processors, XT, Oracle and Saxon, have surpassed the other C/C++ implementations to take 2nd through 4th place respectively. This suggests that high-level optimizations are more important than the implementation language in determining overall performance. The C/C++ processors tend to show more variation in their performance from test case to test case, scoring some very high marks alongside some disappointing performance. XSLTC aside, the C/C++ processors won first place in 33 of the 40 test cases, in some cases scoring two to three times as well as their Java competitors (attsets, dbonerow). This suggests that there is a lot of potential to be gained from using C/C++, but that consistent results might be harder to obtain.
The alpha release of Sun's XSLTC is the first compiler to be included in an XSLTMark benchmark. Although its performance on certain test cases is very promising, XSLTC's compliance is still quite spotty. We look forward to future releases of this software.
XSLT processors have improved substantially since the last XSLTMark release in November. It is especially encouraging to see such dramatic changes in certain processors, such as Xalan Java, over so short a time. Unfortunately, although most of the processors we reviewed were very fast on certain test cases, all of them suffered from poor performance in other areas. In addition, only Saxon was able to correctly execute all forty test cases. Ultimately, no processor has emerged as a clear winner in both performance and compliance.
Update (2001/04/04): Since the publication of this article it has been brought to our attention (thanks to Dan Holmsand and Michael Kay) that some of the older XSLTMark drivers did not follow the convention of excluding XML input parse time from the transformation time measurement. For some of the test cases this can have a significant effect on the score. This discrepancy between the stated intent (of measuring only the transformation time) and the actual source code had actually existed since the first release in October 2000, but was not detected until now. The XSLTMark drivers for the following processors had suffered this additional performance penalty when benchmarked: XT, Saxon, XalanJ, Sablotron and XalanC. Preliminary tests show that taking this into account does not alter the overall balance of power in XSLT performance and dislodge any of the top performers from their superpower status, but it does affect the results significantly.
Changes will be made to put all processors on a level playing field again, but it cannot be done as promptly as desired. The difficulty lies in the fact that some processors simply do not have an easily accessible API's for separate parsing followed by transformation, so it is not a quick change to fix their drivers to separate the parse step. For example, passing a DOM via the standard TRAX API to Saxon will still force it to rebuild the tree for every iteration.
Since it will take some time for the next set of results to be published, we wanted to promptly advise everyone of this error and provide an updated bar chart where the results for the two groups of processors are explicitly segregated. It is still perfectly reasonable to compare processors within a group, but caution should be exercised comparing between groups. Other than making this distinction clear we decided not to modify the results in any way. The next XSLTMark version will include updated drivers and may even change the scoring methodology for all processors.
Table 2: Best Score and Processor
| Test Case | Best Score | Top Processor | Top P+T Processor | Top T Processor |
| alphabetize | 241.09 | MSXML 3.0 | XT 19991105 | MSXML 3.0 |
| attsets | 603.86 | XSLTC Alpha 4 | XT 19991105 | XSLTC Alpha 4 |
| avts | 2348.15 | XSLTC Alpha 4 | XT 19991105 | XSLTC Alpha 4 |
| axis | 429.43 | LibXSLT 0.5.0 | XT 19991105 | LibXSLT 0.5.0 |
| backwards | 299.86 | LibXSLT 0.5.0 | Xalan-J | LibXSLT 0.5.0 |
| bottles | 355.75 | XT 19991105 | XT 19991105 | LibXSLT 0.5.0 |
| breadth | 909.73 | XSLTC Alpha 4 | XT 19991105 | XSLTC Alpha 4 |
| brutal | 605.96 | MSXML 3.0 | XT 19991105 | MSXML 3.0 |
| chart | 399.52 | MSXML 3.0 | XT 19991105 | MSXML 3.0 |
| creation | 1984.80 | XSLTC Alpha 4 | XT 19991105 | XSLTC Alpha 4 |
| current | 155.22 | LibXSLT 0.5.0 | XT 19991105 | LibXSLT 0.5.0 |
| dbonerow | 1344.57 | LibXSLT 0.5.0 | XT 19991105 | LibXSLT 0.5.0 |
| dbtail | 3254.32 | XSLTC Alpha 4 | XT 19991105 | XSLTC Alpha 4 |
| decoy | 559.24 | MSXML 3.0 | XT 19991105 | MSXML 3.0 |
| depth | 524.35 | LibXSLT 0.5.0 | XT 19991105 | LibXSLT 0.5.0 |
| encrypt | 586.50 | XSLTC Alpha 4 | XT 19991105 | XSLTC Alpha 4 |
| functions | 403.39 | XSLTC Alpha 4 | XT 19991105 | XSLTC Alpha 4 |
| game | 706.09 | LibXSLT 0.5.0 | XT 19991105 | LibXSLT 0.5.0 |
| html | 313.64 | LibXSLT 0.5.0 | XT 19991105 | LibXSLT 0.5.0 |
| identity | 2875.92 | XSLTC Alpha 4 | XT 19991105 | XSLTC Alpha 4 |
| inventory | 554.71 | XSLTC Alpha 4 | XT 19991105 | XSLTC Alpha 4 |
| metric | 192.89 | LibXSLT 0.5.0 | Saxon 6.2.1 | LibXSLT 0.5.0 |
| number | 160.94 | MSXML 3.0 | Saxon 6.2.1 | MSXML 3.0 |
| oddtemplate | 119.20 | LibXSLT 0.5.0 | XT 19991105 | LibXSLT 0.5.0 |
| patterns | 616.22 | MSXML 3.0 | XT 19991105 | MSXML 3.0 |
| prettyprint | 255.78 | XT 19991105 | XT 19991105 | LibXSLT 0.5.0 |
| priority | 350.65 | XSLTC Alpha 4 | XT 19991105 | XSLTC Alpha 4 |
| products | 250.78 | MSXML 3.0 | Saxon 6.2.1 | MSXML 3.0 |
| queens | 7.30 | XT 19991105 | XT 19991105 | Oracle XSLT 2.0 |
| reverser | 92.40 | Xalan-Java 2.0 | Xalan-Java 2.0 | MSXML 3.0 |
| stringsort | 838.98 | MSXML 3.0 | XT 19991105 | MSXML 3.0 |
| summarize | 362.26 | XT 19991105 | XT 19991105 | |
| total | 840.69 | XSLTC Alpha 4 | XT 19991105 | XSLTC Alpha 4 |
| tower | 180.57 | XT 19991105 | XT 19991105 | MSXML 3.0 |
| trend | 58.49 | XT 19991105 | XT 19991105 | Oracle XSLT 2.0 |
| union | 183.11 | XSLTC Alpha 4 | XT 19991105 | XSLTC Alpha 4 |
| xpath | 136.45 | XT 19991105 | XT 19991105 | LibXSLT 0.5.0 |
| xslbench1 | 1088.67 | MSXML 3.0 | XT 19991105 | MSXML 3.0 |
| xslbench2 | 1019.73 | LibXSLT 0.5.0 | XT 19991105 | LibXSLT 0.5.0 |
| xslbench3 | 36813.96 | XSLTC Alpha 4 | XT 19991105 | XSLTC Alpha 4 |
| Aggr_Results | 442.61 | MSXML 3.0 | XT 19991105 | MSXML 3.0 |
Acknowledgments
We wish to thank Oren Ben-Kiki for permission to use the queens.xsl stylesheet and Kevin Jones for XSLBench and the permission to use the three xslbench stylesheets. We are also grateful for the support from XSLT engine implementers who provided us with XSLTMark drivers or helped analyze compliance issues: Michael Kay, Andrew Kimball, Berin Loritsch, Steve Muench. Also, thanks to the many other members of the XML Community for their helpful bug reports and suggestions.
Additional Notes
If you are implementing or integrating an XSLT driver that does not currently have an XSLTMark driver, consider writing one and getting it included in the next release. It is important to support as many drivers as possible in a variety of implementation languages on a number of platforms. To our knowledge, XSLTMark has been used so far to test Java, C/C++, Perl, and Python implementations of XSLT processors on Windows, Solaris, HP-UX, and Linux platforms. Some processors currently have drivers, but their benchmark results are not being released at this time, including
- Oracle C++ (no license/permission)
- Smart Transcoder (discontinued)
- Unicorn XSLT (no API, permission)
- Napa (no API)
We welcome comments on the benchmark as well as suggestions for how it can become a better community resource. One of the areas of particular interest to us is assessing the memory footprint of different processors, something that's difficult to measure but of considerable value in production deployments.
For additional information and benchmark download, see http://www.datapower.com/XSLTMark/