Using XML for Object Persistence
September 8, 1999
Applied XML Tutorial
|
Contents |
|
• Part 1:
Using XML for Object Persistence |
What does "object persistence" or "serializing an object" mean and how can XML help with it? Several technologies out there try to assist you in serializing objects into XML strings. They deal with Java, CORBA and COM-objects, so you should take a look at them.
But right now, if you don't yet feel comfortable diving into pages and pages of documentation, stay with me. I'll take you on a tour through object persistence, so you'll know what to expect from the already available technologies. You'll also learn how to implement some persistence strategy yourself.
The article is accompanied by an XML schema and sample code written in Visual Basic 6.0 using Microsoft's MSXML component.
Object Persistence = Storing an Object's Data
Most of you are familiar with using objects in your programs. Often you're using third party objects like an XML parser object or a database API wrapped in an object model, such as Microsoft´s ActiveX Data Objects (ADO). Or you are setting up an object model in your application yourself, like Microsoft Word does. Your object model can be viewed as the ideal representation of your application's data in memory. Maybe you are programming the next 3D killer application and your object model looks like the one in Figure 1.
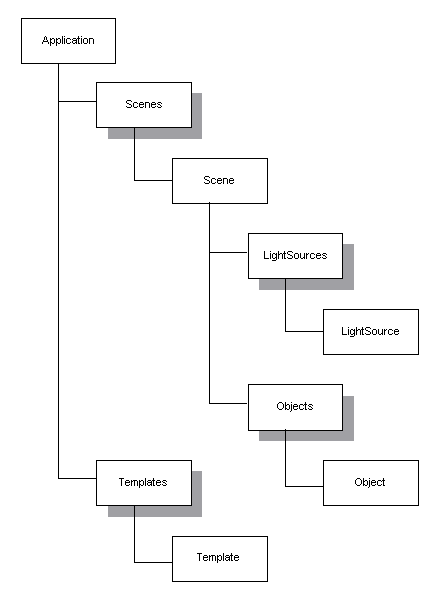
Figure 1: A simple object model.
An object model like this works very well as long as the application is running. But what do you do, when the user wants to close the program? You have to store your objects. Or, to be more precise, you have to store the data of your objects somewhere, such as in a file or in a database. While objects live in memory, data and code (object methods) stay together in "little boxes" (the objects). But when you store an object, you store only the data.
Later, you might create a new, empty object and load the data previously stored by another object. The data is thereby again associated with code.
When storing an object, you separate data from code. Object persistence is all about extracting the information in an object so it is not lost when the object itself is destroyed. Once the data is separated from the object, it can be saved in a file or sent over the Internet to some other computer. Sometimes, objects are supposed to not only store their data but also their code. That's cool, too, and has its uses (for example, in mobile agent scenarios), but we won't discuss that in this article.
Serializing an Object's Data
You may not have ever realized it, but object persistence is something you have already
been working with all along. Whenever you've saved an object's data you made it persistent.
Maybe you have a customer object in your application. Every time you issue an SQL
Update statement to your RDBMS to store the customer's data, you're
persisting the object's data.
When serializing an object, however, the focus is not so much on storing an object's data on non-volatile media, but on how the in-memory data structure of an object differs from how the data looks once it has been extracted from the object. Figure 2 shows you the difference.
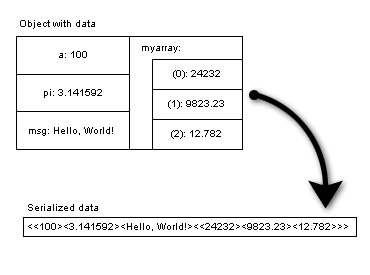
Figure 2: Serializing an object's data
In memory, the data is located at arbitrary addresses which you can think of as arrays, structures, objects, and so on. But those data structures cannot be stored directly. You can only store data with simple types, such as integers, floating point numbers or strings. An array of strings has to be broken up into its parts which are of a simple type. Objects, as another type of complex data structure or container of other data structures, cannot simply be stored either. So we have to break them up into their data parts (properties) and store them individually.
Now, when you want to store several data items in a file, you put them one after the other. A complex data structure -- for example, a multidimensional array -- thus gets written out one array cell at a time, one after the other. That's what serialization means. When serialization takes place, the simple data types in complex data structures get lined up like pearls on a string. Look at Figure 2 and notice how the serialized data items are listed in the string on the right side. Quite literally the serialized form of an object is the one-dimensional representation of its (potentially very) complex data, including information on how the data originally was "arranged" in-memory (for example, in arrays or user-defined structures). This information is needed later, when you want to read the data back into some other object.
The serialization code for the object in Figure 2 could look like this (all code in this column is Visual Basic; it should be so simple to read that even if you program in a different language, you should be able to understand it):
Function Serialize() as String
Dim s as String
s = "<"
s
= s & "<" & a & ">"
s = s & "<" & pi &
">"
s = s &
"<" & msg & ">"
s = s & "<"
s = s &
"<" & myarray(0) & ">"
s = s &
"<" & myarray(1) & ">"
s = s &
"<" & myarray(2) & ">"
s = s & ">"
s = s & ">"
Serialize =
s
End Sub
The characters in the string are the serialized representation of the object's data. We could also have stored the data in a database table; that would have been just another persistence medium, but since there the data would not really be stored in a one-dimensional fashion, we would not really have called it serialization.
Note the implications of having an object's data transformed into this kind of serialized form (though not necessarily a string): It can be stored in a file, in a field in a database table, or can be sent over the Internet. It's a byte array, a string, it's easy to handle in many ways on all kinds of platforms.
You can also think of the serialized data as a dehydrated object. All the water (the code, in this metaphor) has been pressed out of the object, leaving only salt and minerals (the data). Later, when you want to get back the whole object, you rehydrate it. You add water to the serialized data by creating an empty object and deserializing the data.
Serialization Problems
|
Contents |
|
• Part 1:
Using XML for Object Persistence |
So far serialization is quite straightforward: set up a new method in your object's class that takes every property worthy to persist and adds it to a string or a byte array, which serves as your serialization data container. But there are a couple of problems you should be aware of. The next few sections will try to address these problems in turn.
How do you separate the data items from one another?
Data items have to be separated in the output "string" (or byte stream) returned from the object serialization process. Otherwise we won't be able to correctly identify them later when we want to read them data back into some new object during de-serialization.
When storing simple two dimensional arrays in a text file (yes, that is also a form of serialization), we usually separate one array dimension from the other by putting them on different lines. Within a dimension the array cells are separated using a semi-colon (;) or tab character.
100;200;300;400
150;230;299;415
99;201;319;399
111;222;333;444
Two different delimiters have to be used: one for each dimension (carriage-return-line-feed and ";" in the above example). That's okay, as long as you know exactly how many dimensions your data is made up of. But be careful: the delimiter characters must not occur within the data items. (But don't be bothered by this too much right now, it won't be a problem when you read on.)
How do you preserve hierarchical structures?
If you don't want to have to reconsider data serialization formats for all your different objects, you need to come up with a general data format suiting all your objects' needs. However, then you cannot safely assume a fixed number of data dimensions, so you cannot define a fixed number of delimiters. The general problem you face here is how to delimit arbitrary nested data, that is, truly hierarchical data structures. (Multi-dimensional arrays, which you might not immediately think of as being some sort of hierarchical data structure, can however be mapped into a hierarchy of nested one-dimensional arrays.)
You delimit nested data items as you would write mathematical expressions: you use parenthesis. The above code sample does exactly that. It uses angle brackets (< and >) to delimit a data item. A data item is either a simple type value, such as a number or a string, or a data structure made up of simple type values or other data structures.
By using two different delimiters to mark the start of a data item and its end, it is easy to nest data items. You just have to be careful to open a data item and not "close" it before all contained data has been serialized. By bracketing data correctly, a container is created which can hold other containers.
This is also one of the rules of well-formed XML. The above sample is just much more simple in that it uses the same delimiters for all data items and all nesting levels. XML, though, adds information by allowing an arbitrary number of delimiters. Here's the above data serialized into an XML string:
<SerializedData>
<a>100</a>
<pi>3.141592<pi>
<msg>Hello,
World</msg>
<myarray>
<item>24232</item>
<item>9823.23</item>
<item>12.782</item>
</myarray>
</SerializedData>
How do you deserialize the data?
In a nutshell we've so far followed part of the reasoning behind XML: how to mark up arbitrarily nested data. So why not use XML as the target data format for serialized objects? XML data is a string and it allows us to store hierarchical information. Also XML comes in very handy when you think about deserializing a dehydrated object. Before XML you had to write your own low-level import routine to extract the data items from maybe a tab-delimited file or your own data format. But with XML you can safely rely on the XML parser to do that for you. You lean back and pick the data items from the XML DOM tree produced by the parser. Look at this example working on the above XML data passed into the routine as a string. (It's using the Microsoft MSXML-component of IE5; reading in the myarray-data is left out for brevity.)
Sub Deserialize(byval data as String)
Dim xml as new
MSXML.DomDocument
xml.LoadXML data
Dim dataItem as MSXML.IXMLDomNode
For Each dataItem in xml.documentElement.childNodes
Select Case dataItem.nodeName
Case
"a"
a = dataItem.text
Case
"pi"
pi = dataItem.text
...
End Select
Next
End Sub
XML lets you concentrate on the semantics of your data, such as which data item to store where (for example, the <a> element's text goes into variable a). The syntax (where does a data item start in the stream of bytes of serialized data) is taken care of by the XML parser.
How do you preserve object relationships?
So far we've seen how to serialize simple data types and common data structures like arrays. Now if you look back at Figure 1 you see not just one object, but several ones linked together in a hierarchy. When you want to persist or serialize the root object of this object tree, you certainly mean to also serialize the objects linked to it. But how do you store object references (pointer to objects in memory) or the linked objects themselves? One way would be to treat them like nested data structures:
<Application>
<name>My 3D
Application</name>
...
<Scenes>
<Scene>
<title>Dark Side
of the Moon</title>
<LightSources>
<LightSource>
...
</LightSource>
</LightSources>
<Objects>
<Object type="sphere">
...
</Object>
<Object type="cylinder">
...
</Object>
</Objects>
</Scene>
<Scene>
...
</Scene>
...
</Scenes>
<Templates>
<Template>
...
</Template>
</Templates>
</Application>
Each object's data is nested within its parent object data. Looks nice, works fine -- unless you must deal with multiple references to one object or circular references (an object references itself either directly or indirectly through other objects it is pointing to). If two objects reference the same third one, it would have to be included within the serialized representation of both referencing objects. That would destroy the object's identity, which in-memory is based not on its content (the data) but on its memory address.
A much better way is to not nest objects at all. Compare the following XML data to the above:
<Objects>
<Application id="0">
<Scenes>
<Item
refId="1"/>
<Item
refId="2"/>
</Scenes>
<Templates>
<Item
refId="8"/>
<Item
refId="9"/>
</Templates>
</Application>
<Scene id="1">
<TemplateRef refId="9"/>
<LightSources>
<Item
refId="3"/>
</LightSources>
<Objects>
<Item
refId="5"/>
<Item
refId="6"/>
</Objects>
</Scene>
<Scene id="2">
...
</Scene>
<LightSource
id="3"/>
<LightSource
id="4"/>
<Object id="5"/>
<Object id="6"/>
<Object
id="7"/>
<Template id="8"/>
<Template id="9"/>
</Objects>
All objects reside on the same level (right below <Objects>). Every object has been assigned a unique ID, thus object references could be serialized into references by ID. This XML data format effectively defines its own address space where each ID is an address and an object is the smallest addressable memory unit.
The object relationships might not be as obvious as when object data was nested, but it is a more general way of serializing arbitrary networks of objects.
XML Object Persistence: Roll Your Own Generic XML Data Format for Object Serialization
|
Contents |
|
• Part 1:
Using XML for Object Persistence |
Now, after the above somewhat theoretical discussions, we want to see, how the concepts can be implemented to benefit one of your next projects. The following code is supposed to demonstrate how object serialization can be done. It is not meant to solve all problems associated with object persistence, nor to be a replacement for any of several supported technologies and efforts. But I hope, you´ll see how rewarding using XML can be.
What Do We Want to Accomplish?
We want to have an easy means of serializing and deserializing objects. The serialization format should be an XML string, which can easily be stored in a file, in an RDBMS table field, sent over a network or passed as a procedure parameter (also called marshaling the object). As application programmers we don't want to be bothered with lots of additional code to accomplish this. So here's our vision of how easy serializing a network of objects should be for a user:
Dim myObject as new MyClass, serializedObject as String
...
serializedObject = Serialize(myObject, false)
...
Dim myObject2 as MyClass
Set myObject2 = Deserialize(serializedObject)
As users of the object we don´t want to care about how complex its internals are or whether it is linked to other objects. We just want to serialize it and be sure all information is preserved. That means
- all object properties must be serialized,
- all object properties must retain their types, and
- any persistent objects referenced by the object must also be serialized. (Non-persistent objects, such as transient objects, need not to be serialized.)
These are reasonable demands, and as we will see, they can be fullfilled by the ObjectStore component we are going to build. ("ObjectStore" seemed a good name for the service, but please don't confuse it with the like named ODBMS product from Object Design, Inc.) We've already seen the two only methods of our ObjectStore object: Serialize and Deserialize.
A note for VB developers: By declaring the ObjectStore VB-class in our sample project as GlobalMultiUse, an instance of it always gets created automatically when running an application referencing it. So we don't need to create an instance ourselves and also do not need an object variable as a qualifier for the methods.
How Does a Serializied Object Look?
The goal is set, we know how we want to use the serialization mechanism, we know what it is supposed to accomplish, but how should the serialized data look? Here's an example of what the ObjectStore implementation´s XML serialization format looks like:
<?xml version="1.0" encoding="ISO-8859-1"?>
<ObjectStore version="1.0" xmlns="x-schema:xop-schema.xml">
<Object id="id1234"
classname="Project1.Class1">
<string name="stringVar"
xml:space="preserve">John Doe</string>
<int name="intVar">32</int>
<float
name="floatVar">3.141592</float>
<boolean name="booleanVar">1</boolean>
<dateTime
name="dateTimeVar">1999-08-16T12:45:17</dateTime>
<objectRef
name="objectRefVar">id9876</objectRef>
<struct
name="udtVar">
<string name="stringVar">Henry Doe</string>
<int
name="intVar">65</int>
</struct>
<array name="arrayVar"
lowerBound="0" upperBound="2">
<int
name="0">10</int>
<int
name="1">9</int>
<int
name="2">8</int>
</array>
</Object>
<Object id="id9876"
classname="Project1.Class1">
...
</Object>
</ObjectStore>
Let's have a closer look at the structure of a serialized object.
<ObjectStore> as a container of objects
The document element <ObjectStore> serves as a container for all the objects that get serialized during a call to the Serialize method. As we found out above, nesting objects into one another is not really the way to go, if you want to be able to serialize arbitrary networks of objects. But that's exactly what the ObjectStore is supposed to do: be independent of any particular object hierarchy. It should be able to serialize any ever so intricately intertwined mesh of objects. Therefore it sets up the <ObjectStore> element as a little "universe" of objects which therein exist in parallel, on the same level.
The version attribute gives us a way to recognize possibly older versions of serialized data and treat them differently from more current versions. It's an attribute to be interpreted by the ObjectStore component.
The xmlns attribute attaches an XML schema definition to the data so it can be validated. We'll discuss that further below.
<Object> as a container of an object's data
Each object serialized gets stored in its own element. To allow an object to be referenced by another one, the <Object> element has an id attribute which identifies it uniquely within the set of all objects in the ObjectStore´s object universe. It is a kind of an address for the object, though not in memory.
The classname attribute is necessary to enable the ObjectStore to create a new, empty instance for an object's data during deserialization. Imagine the serialized data being sent over a network to another computer. How should the ObjectStore on that machine determine what kind of object the serialized data belonged to? How could it create a new object of the same kind to be filled with the data? Without some hint as to how to create a new instance of the original object this would be impossible. The classname is that hint. It can be a Java class name or a COM progID. The only requirement is it must be understood by the ObjectStore trying to deserialize an object´s data. More about this below.
Simple type properties
Each object property of a simple type (integer, floating point number, string) is serialized into an element according to its type. Data type names are used as tag names, not the names of the object´s properties. But why would we do that? There are two reasons:
- ability to validate ObjectStore XML documents
- preservation of property data types.
Again, more about that later.
Instead of
<myproperty type="integer">1234</myproperty>
we write
<int name="myproperty">1234</int>
It's equally easy to understand and follows other initiatives (such as SODL, WDDX). By attaching a name to the element, though, our little XML language is more compact than, for example, WDDX. In WDDX we'd have to write:
<var name="myproperty">
<number>1234</number>
</var>
See the complete schema definition (as well as the above XML sample) for a list of all simple data types supported by our ObjectStore.
Data structures
For the purpose of this article only two data structures can be serialized with the ObjectStore component in the sample project: user defined types (UDT, like a C struct) and arrays.
A <struct> element is simply a nested container of properties (like the <Object> element is). It has a name of its own and each of its members is also named. That way addressing properties within a <struct> can be as straightforward as accessing members of a UDT:
Type myStruct
name as String
age as
Integer
End Type
Dim person as myStruct
person.name = "John"
person.age = 46
The <struct> element for the UDT would be:
<struct name="myStruct">
<string
name="name" xml:space="preserve">John</string>
<int name="age">46</name>
</struct>
And serializing the person UDT-variable would look like this:
Store "person.name", person.name
Store "person.age",
person.age
Whereas <struct> elements contain named members (mostly of different types), <array> elements contain unnamed, but indexed members (mostly of the same type). The array
Dim myarray(5 to 6) as Integer
myarray(5) = 1234
myarray(6) = 9876
would be serialized into
<array name="myarray" lowerBound="5"
upperBound="6">
<int
name="5">1234</int>
<int
name="6">9876</int>
</array>
Arrays in our sample implementation can only be one-dimensional. Although, like <struct> elements they can be nested:
<struct...>
...
<struct...>
...
<struct...>
</struct>
...
</struct>
...
</struct>
<array...>
...
<array...>
...
<array...>
</array>
...
</array>
...
</array>
The ObjectStore component recognizes the type of each array element and nests the elements if necessary.
In addition to these data structures other, more complex data structures could also be implemented, so as to be automatically serializable. For example ADO 2.5 Recordset objects could be streamed into an XML representation and then inserted to the ObjectStore XML data tree. WDDX, for one, already sports a special <Recordset> element.
Object references
Serializing object references is as easy as serializing simple type properties.
<Object id="id123"...>
...
<objectRef
name="child">id987</objectRef>
</Object>
<Object id="id987"...>
...
</Object>
The value of an <objectRef> element is the id of an <Object> element in the <ObjectStore>. This way unidirectional, bidirectional (circular) and self-referential object relationships can be serialized. Each object gets serialized only once. Thus object identity is preserved.
Note: No special XML linking technology is used, because it would not provide any advantage. All object references point to locations within the same XML document and need only be interpreted by a dedicated processor (the ObjectStore component). See below for how it´s done.
How Do We Ensure the Formal Correctness of a Serialized Object?
The task of the ObjectStore component is to ("semantically") interpret the XML DOM generated by the XML processor form the serialization data. To be able to focus on this task, we should offload as much work as possible from it that is "more low level". By using a validating XML parser and a schema definition we can ensure ObjectStore of all XML data it receives will be well-formed and valid XML representing serialized objects.
A DTD as well as an XML schema (see http://msdn.microsoft.com/xml/reference/schema/start.asp for details on the XML schema preview implementation in the MSXML component) define which elements and attributes constitute a particular XML language. XML itself and its DTD, though, do not have a concept of data types. But the schema languages under development do (see http://www.w3.org/XML/Activity.html for an overview). Also the XML schema preview implemented by Micorosoft´s MSXML component lets you define elements and attributes being of a particular type. In addition to that, XML schemas are written in XML, whereas DTDs have a completely different syntax.
The ObjectStore XML language for object serialization - lets call it the XML Object Serialization (XOP) data format - is defined using XML Schema because of its advantages over DTDs. Let´s look at an excerpt:
<Schema name="xop"
xmlns="urn:schemas-microsoft-com:xml-data"
xmlns:dt="urn:schemas-microsoft-com:datatypes">
<!-- general attribute definitions -->
<AttributeType name="name" dt:type="string" required="yes"/>
<!-- definition of ObjectStore element
hierarchy -->
<ElementType
name="ObjectStore" content="eltOnly" model="closed">
<AttributeType name="version" default="1.0" dt:type="string"/>
<attribute type="version"/>
<element type="Object" minOccurs="1"
maxOccurs="*"/>
</ElementType>
<ElementType name="Object"
content="eltOnly" model="closed" order="many">
<AttributeType name="id" dt:type="id"
required="yes"/>
<AttributeType
name="classname" dt:type="string" required="yes"/>
<attribute type="id"/>
<attribute type="classname"/>
<element type="string" minOccurs="0"
maxOccurs="*"/>
<element type="int"
minOccurs="0" maxOccurs="*"/>
<element
type="float" minOccurs="0" maxOccurs="*"/>
...
</ElementType>
...
<!-- definition of elements for simple type
object properties:
each property
is stored in an element whose tag name
matches the data type of the property
-->
<ElementType name="string"
content="textOnly" dt:type="string">
<attribute type="name"/>
</ElementType>
<ElementType name="int" content="textOnly"
dt:type="int">
<attribute type="name"/>
</ElementType>
<ElementType name="float" content="textOnly"
dt:type="float">
<attribute type="name"/>
</ElementType>
...
</Schema>
In the XML Schema preview you define an XML element for your XML language using <ElementType>. Then you state where the element is allowed to appear, that is, with which other elements, by using <element>. The same goes for attributes.
So by definining our elements and putting a couple of constraints on them, such as,
content="eltOnly" model="closed" order="many"
we have clear rules on how a XML string "pretending" to contain serialized objects should look. By including a reference to the XML schema in every XOP string the MSXML parser can check the data before the ObjectStore actually uses it. The reference to the schema has to be included as an attribute in the document element:
<ObjectStore version="1.0"
xmlns="x-schema:xop-schema.xml">
By working only with validated XML data the ObjectStore component can make certain assumptions and needs less error handling code. It´s more focused on the task at hand: deserializing objects from an XOP string.
In addition to that, the XML schema preview allows the definition of a type for element content and attribute values. For example:
<ElementType name="int" content="textOnly"
dt:type="int">
The data type dt:type="int" limits the text contained in an <int> element to strings representing a 32-bit integer number. The element
<int name="a">123</int>
would be valid according to the above definition, however the element
<int name="b">hello123</int>
would not. Even though it is well-formed XML and conforms to the syntactical rules of XOP (structure of elements, hierarchy of elements) it violates the semantics of the type definition. The element's text cannot be converted to an integer value.
By including type information in the schema we assure the ObjectStore component, that the data contained in the elements representing the object properties is correct according to the properties' data types.
Since element data types have to be declared in the schema, we have to know in advance, which elements to expect in an XOP string. That's the reason why we are using a limited number of tag names (the data type names) instead of an unlimited number (property names).
The Plumbing: Serializing an Object
Now, that we know what we want and how the serialized object data is supposed to look, let's see how we can implement the ObjectStore component.
The sample project consist of a test project (project1.vbp) defining a persistent class (Class1) and the persistence manager (persistencemanager.vbp, a COM in-proc server) with the ObjectStore class.
Setting the stage
In order to use the ObjectStore services a VB-project has to do two things:
- include a reference to the persistence manager COM-component, and
- implement the IXOP interface (class ixop.cls) in every class to be made serializable.
The IXOP interface is small:
Public Sub LoadProperties(ByVal op As ObjectProperties)
Public Sub
StoreProperties(ByVal op As ObjectProperties)
Public Property Get Classname() As
String
Implementing Serialization in a persistent object
To set a class up for serialization, two methods of IXOP have to be implemented: StoreProperties and Classname. Here´s an excerpt from Class1, which has properties of every type supported by the XOP XML schema:
Implements IXOP
Public Type UDT
stringVar As String
intVar As Long
End Type
Public stringVar As String
...
Public objectrefVar As Class1
Public
arrayVar As Variant
Private udtVar As UDT
Private Property Get IXOP_Classname()
As String
IXOP_Classname = "Project1.Class1"
End
Property
Private Sub IXOP_StoreProperties(ByVal op As
PersistenceManager.ObjectProperties)
op.Store "stringVar",
stringVar
...
op.Store "objectRefVar", objectrefVar
op.Store "udtVar.stringVar", udtVar.stringVar
op.Store "udtVar.intVar", udtVar.intVar
op.Store "arrayVar", arrayVar
End Sub
IXOP_Classname just returns the progID of the class to be included in the <Object> element. Later we´ll see how it is used to create new objects during deserializatoin.
The bold code parts above show how different type of properties are serialized. Since the object itself knows best, which information to make persistent, we give it the responsibility to pass whatever data items it deems worthy to the persistence manager. For that purpose the ObjectStore hands to the persistent class object an ObjectProperties object. (Those of you familiar with VB6 may recognize the similarity of this approach to using class persistence and the PropertyBag object. However, the XML approach we are following here is more flexible in several ways: It's platform independent, it's language independent, and it does not rely on CLSIDs for deserialization.)
For the purpose of serialization, the ObjectProperties object offers the Store method. It accepts as parameters the name of the property to be serialized and its value. Simple type values, one-dimensional arrays, and object references (to objects also implementing IXOP) can be passed to it. However UDTs have to be passed member by member, since the ObjectProperties object has no way of "looking into" a UDT variable and "see" which members it has.
How serialization works
This is how we wanted to serialize an object:
Dim c as New Class1
c.stringVar = "Hello, World!"
debug.print Serialize(c, false)
We call this the Serialize method of the ObjectStore component. But how does it call the IXOP_StoreProperties method of our object and serializes everything into an XOP string? First look at a simplified sample procedure call stack:
ObjectStore.Serialize(myObject)
ObjectStore.SerializeObject(myObject)
myObject.IXOP_StoreProperties(objectProperties)
objectProperties.Store(propertyName, propertyValue)
objectProperties.StoreProperty(propertyName,
propertyValue)
[objectProperties.Store???
| ObjectStore.SerializeObject(propertyValue)]
Serialize calls the IXOP object and passes it an ObjectProperties object, which then gets called for every property from within the IXOP_StoreProperties. This leads to further method calls within the ObjectProperties object and possibly to a recursive call to the ObjectStore. But lets have a closer look at how everything starts. Here's an excerpt from SerializeObject, a method, that gets called from Serialize and does most of the work.
First the object to be serialized is added to the object cache. The cache contains all objects so far serialized and of course we check it first, before we serialize an object. If it's in there already, we don't do anything. This is to preserve object identity: every object gets serialized only once.
m_objectCache.Add rootObject, id
Then we create the <Object> element for the object. It's later
appended to the list of objects in <ObjectStore> represented by
m_xop:
Dim objNode As MSXML.IXMLDOMNode, a As MSXML.IXMLDOMAttribute
Set objNode =
m_xop.createNode(NODE_ELEMENT, _
"Object", m_xop.documentElement.namespaceURI)
Note how the XML schema namespace is used during creation of the new element.
Even though the XML schema namespace was set up as the default namespace of the
<ObjectStore> element in m_xop (see Serialize in the sample
code for details), later validation of XOP strings was only successful when the namespace
was used whenever creating a new element (this is a glitch in the Microsoft MSXML
component).
Then we add the id of the object (generated from the object´s address) to the <Object> element as an attribute as well as the classname:
Set a = m_xop.createAttribute("id")
a.nodeValue = "id" &
ObjPtr(rootObject)
objNode.Attributes.setNamedItem a
Set a =
m_xop.createAttribute("classname")
a.nodeValue = rootObject.Classname
objNode.Attributes.setNamedItem a
m_xop.documentElement.appendChild objNode
After that we are ready to serialize the properties into the newly created
<Object> element by calling IXOP_StoreProperties of the persistent
object:
Dim op As ObjectProperties
Set op = New ObjectProperties
op.Constructor Me, objNode
rootObject.StoreProperties op
Set op = Nothing
The workhorse method in the ObjectProperties class during serialization is StoreProperty. It gets indirectly called by the object to be serialized from within the IXOP interface. Here´s an excerpt from the function:
Private Sub StoreProperty(ByVal parentNode As MSXML.IXMLDOMNode, _
ByVal propertyName As String, ByVal value As Variant)
If
InStr(propertyName, ".") = 0 Then
Dim p As
MSXML.IXMLDOMNode, nodeName As String, _
a As MSXML.IXMLDOMAttribute
Select Case TypeName(value)
Case "String"
nodeName = "string": GoSub StoreSimpleTypeValue
Set a = parentNode.ownerDocument.createAttribute("xml:space")
a.nodeValue = "preserve"
p.Attributes.setNamedItem a
Case "Byte",
"Integer", "Long"
nodeName = "int": GoSub StoreSimpleTypeValue
...
Case Else
If IsObject(value) Then
value = m_os.SerializeObject(value)
nodeName = "objectRef": GoSub StoreSimpleTypeValue
...
Exit Sub
StoreSimpleTypeValue:
Set p = parentNode.ownerDocument.createNode(NODE_ELEMENT,
nodeName, _
parentNode.namespaceURI)
Set a =
parentNode.ownerDocument.createAttribute("name")
a.nodeValue = propertyName
p.Attributes.setNamedItem a
p.appendChild
parentNode.ownerDocument.createTextNode(value)
parentNode.appendChild p
Return
End
Sub
The value passed to the function is handled according to its type (typename(value)). Simple types are simply stored in an element named according to their type (StoreSimpleTypeValue), for example, <int>. And more complex types (arrays, UDTs) are passed to special functions and then stored in <array> or <struct> elements.
Please note, how SerializeObject is called recursively to serialize an object passed as a property value. It returns the id generated for the object which then gets serialized like any string data item. The object itself is stored somewhere else in the XOP XML DOM -- or maybe it had already been serialized so just a reference to it was retrieved.
The Plumbing: Deserializing an Object
Once you understand serialization, deserialization is usually just doing the same thing, but the other way around. Let's follow the process step by step starting with the call of Deserialize.
First we create an XML parser object and load the XOP string, thereby validating it against the XOP XML schema. The XOP data is either passed directly in the xopSource parameter or it is contained in a file, whose filename is in xopSource. The method checks how to load the data by looking at the first character in the xopSource string. If it´s a "<" it assumes xopSource contains the XOP data, otherwise it assumes xopSource is a filename.
Public Function Deserialize(ByVal xopSource As String) As Object
Set m_xop = New MSXML.DOMDocument
m_xop.async = False
If Left$(xopSource, 1) = "<" Then
m_xop.loadXML xopSource
Else
m_xop.Load
xopSource
End If
If the XOP data is valid and the XML DOM has been built by the MSXML XML parser, we initialize the object cache. The cache will hold references to all deserialized objects. Whenever an object is referenced by an <objectRef> element it is first looked up in the cache. Only if not yet present, the ObjectStore will locate it in the XOP XML DOM and deserialize it.
The deserialization starts with the first <Object> element in the XOP data. The XML schema guarantees there is one by defining a minOccurs="1" for it within <ObjectStore>.
If m_xop.parseError.errorCode = 0 Then
Set m_objectCache = New Collection
Set Deserialize =
DeserializeObject(m_xop.documentElement.selectSingleNode("Object")._
Attributes.getNamedItem("id").nodeValue)
Set m_objectCache = Nothing
Else
...
Please note how the MSXML method selectSingleNode (this method is not XML DOM spec compliant) is used to get at the first <Object> element. The same could of course have been accomplished using just XML DOM specification conformant methods - it would only have taken a couple of more lines of code.
Creating empty object instances
De-serializing an <Object> element is straightforward:
Friend Function DeserializeObject(ByVal objId As String) As Object
Dim obj As IXOP, objNode As MSXML.IXMLDOMNode
On Error Resume Next
Set obj = m_objectCache(objId)
If Err <> 0 Then
On Error GoTo 0
Set objNode =
m_xop.documentElement.selectSingleNode("Object[@id='" & objId & "']")
Set obj =
CreateObjectFromClassname(objNode.Attributes.getNamedItem("classname").nodeValue)
m_objectCache.Add obj, objId
Dim op As ObjectProperties
Set op = New ObjectProperties
op.Constructor Me, objNode
obj.LoadProperties op
Set op = Nothing
End If
Set DeserializeObject = obj
End Function
First check the cache if the object has been deserialized already and if so, return the reference to it. If not, locate its <Object> element, create an empty instance and fill the instance by calling its IXOP LoadProperties method with an ObjectProperties object full of data.
The exciting part here is how an empty object instance is created from the classname attribute.
Private Function CreateObjectFromClassname(ByVal Classname As String) As IXOP
Dim obj As IXOP
RaiseEvent RequestObject(Classname, obj)
If obj Is Nothing Then
On Error Resume Next
Set obj = CreateObject(Classname)
End If
Set CreateObjectFromClassname = obj
End Function
The ObjectStore component uses two approaches. First it tries to ask the application for an instance. It does so by firing the event RequestObject. If the application has registered itself as an event sink for this event, it creates an object matching the class name however it likes:
Private Sub myObjectStore_RequestObject(ByVal classname As String, newObject As
PersistenceManager.IXOP)
Select Case classname
Case "Project1.Class1"
Set newObject = New
Class1
End Select
End Sub
If, on the other hand, the event raised returns with no object assigned to obj, the ObjectStore tries to create an instance using a standard COM technique: calling CreateObject. For this the classname must be a COM progID of a class registered on the machine where the ObjectStore is running.
Interpretation of the classname attribute thus rests on two shoulders: the application and the ObjectStore. It is not dependent on any programming language or platform.
Deserializing the data
The workhorse during deserialization in the ObjectProperties class is LoadProperty. Here's an excerpt:
Private Sub LoadProperty(ByVal parentNode As MSXML.IXMLDOMNode, _
ByVal propertyName As String, _
ByRef propertyValue As Variant)
If InStr(propertyName, ".") = 0
Then
Dim pNode As MSXML.IXMLDOMNode
Set pNode =
parentNode.selectSingleNode("*[@name='" & propertyName & "']")
Select Case pNode.nodeName
...
Case
"objectRef"
Set propertyValue = m_os.DeserializeObject(pNode.Text)
Case Else
propertyValue = pNode.nodeTypedValue
...
End Select
As long as a property name contains a period (.) it is interpreted as a
<struct> name and LoadStructMember is called (not shown here).
Otherwise it's a "regular" property whose element is located in the
childNodes collection of the parentNode. selectSingleNode is used to
find the element.
The select statement determines how it is to be deserialized. For simple type data items the value of the element is assigned to the ByRef-variable used as a return value. Since we are using XML schema data types, nodeTypedValue contains the already properly converted data value, not a string (that could be found in the nodeValue or text properties); no conversion on our side is necessary. The parser has done that already.
Deserializing object references is almost like deserializing simple type values: We just call DeserializeObject recursively and it takes care of everything. The value of the property element is the id of the object we are linking to and it is passed to the method.
Conclusion
As you can see, serializing objects is no black art. It's fairly simple to implement if you are careful -- even with a language like Visual Basic. And using XML as the basis for serialized data is an ideal choice for several reasons:
- It's easy to "read" and understand.
- It's platform and language independent.
- It can store intricate networks of objects.
- It can can be validated.
- It has a text format that can be passed over a wire or stored in a file.
- Import tools (XML parsers) are readily available and take of a lot of the burden off the deserialization process.
So regardless if you are working on a document-centric application, a database program or some other application, don't twice when you need to persist objects. Use XML and some kind of ObjectStore component. Please don´t get me wrong: Of course, the concepts presented herein are not supposed to replace RDBMS or ODBMS. Only real database products can handle large amounts of data and provide sophisticated functionality like transaction processing.
But there are so many cases where you just need to store objects in a file or pass them as parameters to some method running on another machine -- maybe on the other side of the Internet. This is where XML based object persistence shines.
If you have any comments on this article, liked it, disliked it, want to share some thoughts: let me know.