XSL Considered Harmful, Part 2
May 20, 1999
XSL Considered Harmful (Part 2)
In this section we will compare the effectiveness of XSL to the DOM for transforming XML documents and we'll show where the DOM+CSS approach goes way beyond XSL in enabling the scripting of dynamic, interactive behavior in truly Web-oriented XML applications.
 The original
XSL application was developed by Microsoft. It can be run (on IE5 browsers) at http://msdn.microsoft.com/xml/samples/stock-sorter/stock-sorter.xml A zip file of all
the necessary files is available at http://msdn.microsoft.com/xml/samples/stock-sorter/stock-sorter.zip. According to
Jonathan Marsh, Program Manager, XSL at Microsoft, the example currently at the above
URLs
expands on the application described in this article with the addition of data-typed
sorting, number formatting, and simple data-driven formatting changes. The author
did not
have a chance to look at these changes before we went to press.
The original
XSL application was developed by Microsoft. It can be run (on IE5 browsers) at http://msdn.microsoft.com/xml/samples/stock-sorter/stock-sorter.xml A zip file of all
the necessary files is available at http://msdn.microsoft.com/xml/samples/stock-sorter/stock-sorter.zip. According to
Jonathan Marsh, Program Manager, XSL at Microsoft, the example currently at the above
URLs
expands on the application described in this article with the addition of data-typed
sorting, number formatting, and simple data-driven formatting changes. The author
did not
have a chance to look at these changes before we went to press.
The XSL application can only be run in IE5. It is not W3C Recommendation compliant as XSL is not currently a Recommendation of the W3C. I do not know if this application adheres to the most recent revision of the XSL Working Draft but judging from the comments in Mr. Holman's paper about "msxsl" I gather that this is not likely.
The DOM+CSS application is compliant with current W3C Recommendations and can be run in any browser which supports them. At this moment that includes at least the Gecko builds at www.mozilla.org and DocZilla at www.doczilla.com.
The XSL Stock Sorter
This application sorts the rows of a table based on values in any individual column by clicking on the header of the column. The sort is straight ASCII (z comes before A) string sort and it does not handle numeric or other types of values.
The file downloaded to the browser is XML. XSL is used to convert the XML into an HTML table. Each table header has a nested Div tag with an onClick event to invoke the XSL sort, passing the name of the field to be sorted to the routine. The entire document is regenerated in HTML each time the table is sorted.
By the way, the time and date is hard-coded into the demo. I may as well give away now that the JavaScript scripting environment will of course give us many date operations including tricky date conversions (humans like to see dates and times displayed in a variety of ways and computers also have their own ideas about how to represent a date) as well as timer operations which will allow us to trigger our stock updates from the client-side at whatever interval the user desires.
The contents of "sort-stocks.xsl", referenced in the "portfolio.xsl" script, trigger the transformation of the document, I think. It's complicated!
DOM Stock Sorter - Functionality
The functionality is similar to the XSL Stock Sorter - but with some important differences. Type-specific and directional sorting has been implemented, and the default values are actually encoded in the column header (One could imagine being able to change properties of the sort from controls in the page.) There is an XML column header instead of the column headings hard-coded in the script found in the XSL application. Here is a snippet of data showing the header and a row of stock information:
<?xml version="1.0"?>
<?xml-stylesheet href="stuff.css" type="text/css"?>
<portfolio>
<stockhead>
<headrow>
<colhead field="string/g" direct="asc">Symbol</colhead>
<colhead field="string/g" direct="asc">Name</colhead>
<colhead field="curr" direct="desc">Price</colhead>
<colhead field="num" direct="desc">Change</colhead>
<colhead field="units" direct="desc">%Change</colhead>
<colhead field="units" direct="desc">Volume</colhead>
</headrow>
</stockhead>
<stockbody>
<stock>
<symbol>LOVE</symbol>
<name>Love Corp</name>
<price>$18.875</price>
<change>-1.250</change>
<percent>-6.21%</percent>
<volume>0.23M</volume>
</stock>
The colhead field attribute allows one to specify case-insensitive string sorting (/g - z comes after A), currency, numeric, and numeric with a units symbol sorts and the direct attribute states whether the sort should be ascending or descending.
The table is formatted in XML using CSS2 table display properties. Hey, you don't need XSL to create HTML tables if your browser is CSS2 compliant! It looks quite good, if I say so myself:
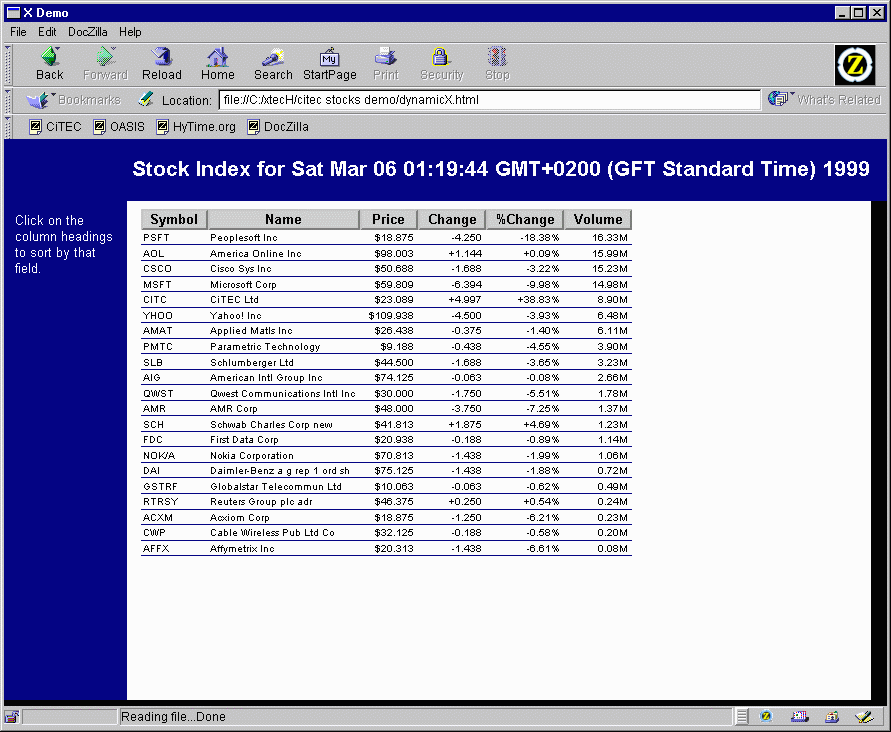
The stylesheet for this application is shown below:
portfolio
{
display: table;
margin-top: 0.5em;
margin-bottom: 0.5em;
margin-left: 0.5em;
}
symbol, name, price, change, percent, volume
{
display: table-cell;
font-family: Arial, Helvetica, sans-serif;
font-size: x-small;
line-height: 1.2;
vertical-align: top;
padding-left: 0.2em;
padding-right: 0.1em;
padding-top: 0.1em;
border-bottom: 1px solid navy;
}
colhead
{
cursor: pointer;
display: table-cell;
font-family: Arial, Helvetica, sans-serif;
font-weight: bolder;
font-size: small;
text-align: center;
line-height: 1.2;
vertical-align: top;
background: #CCC;
color: black;
padding-left: 0.2em;
padding-right: 0.2em;
padding-bottom: 0.05em;
border: 2px inset black;
}
stockhead stock symbol,
stockhead stock name
{
text-align: left;
}
change,
price,
percent,
volume
{
text-align:right;
padding-right: 0.4em;
}
stock, headrow
{
display: table-row;
}
stockhead
{
display: table-header-group;
}
stockbody
{
display: table-row-group;
}
We use the DOM to traverse the elements of the column header and to set an onMouseDown event sort handler for each one. We use DOM operations to also get attribute information to guide the sort and to actually handle the mechanics of rearranging the node.
Of course, we have no need to regenerate the entire document. Another very important point about the DOM approach is that the code is all totally generic - it will work on any table having matrix (no spanned rows or colums) structure and headers.
DOM Stock Sorter - Code
In the main routine four global variables must be declared which are specific to the table markup. An array is created which will hold the table cells and makeSortableTable is called. That is all that is needed to make the table sortable by clicking on column headings. The four global variable which must be declared contain the name of the column header elements, the name of the row container elements and the attribute names used to identify the direction of the sort and the field type.
var gHeaderRowCellGI = "COLHEAD"; var gRowCellGI = "STOCK"; var gSortDirectionAttributeName = "DIRECT"; var gFieldTypeAttributeName = "FIELD"; var gTableCells = new Array(); makeSortableTable(gRowCellGI);
It may be of interest to note that this information could be passed to the application by means of architectural forms, a technique by which any element or attribute can be associated with an abstract element type such as COLHEAD, STOCK or attribute type such as DIRECT or FIELD and thereby entirely avoiding any markup-specific code. (If, of course, the browser has the ability to understand architectural forms.)
Before we go on, I would like to emphasize again - from this point on you are looking at totally generic library functions which can be used with many different XML files and applications - they are library or utility functions. The markup-specific part of our code was the four declarations shown above. An extremely important characteristic of procedural programming languages is that they allow and even strongly encourage reusable module construction.
function makeSortableTable(rowCellGI)
{
We will set up sort event handlers on the cell headers. Compare this to the XSL application's technique of using an onClick attribute in the generated markup. This technique allows one or more event handlers to be set on any XML element at any point in the processing without requiring any special attributes in the markup.
setTimeout(SetSortOnCellHeaderEvents,0);
We get all the row elements and store them in global array. Then we call putDOMNodeIntoSortTable to extract the cell elements in the rows and store them in a two dimensional array ready for sorting.
var celllist = document.getElementsByTagName(rowCellGI);
for (var i=0; i < celllist.length; i++) {
gTableCells[i] = celllist[i];
}
putDOMNodesIntoSortTable(gTableCells);
}
function putDOMNodesIntoSortTable(nodes)
{
var i, j;
var ncount = nodes.length;
for (i = 0; i < ncount; i++) {
var node = nodes[i];
var childNodes = node.childNodes;
var ccount = childNodes.length;
for (j = 0; j < ccount; j++) {
var child = childNodes[j];
node[j] = child.firstChild.nodeValue;
}
}
}
Here is where we do the actual setting of events on column headers discussed above. We get the column headers by the element name specified in our declaration and set an onmousedown event handler called sortOnColumn on each header cell returned in the headerCells array.
function SetSortOnCellHeaderEvents() {
var headerCells = document.getElementsByTagName(gHeaderRowCellGI);
for(var i=0; i<headerCells.length;i++) {
headerCells[i].onmousedown = sortOnColumn;
}
}
sortOnColumn is the event handler invoked when the user clicks on a header cell. First it must get the fieldtype and direction attributes from the column header to invoke the proper sorting for the column. Actually we just iterate over the column header cells until we find a node which matches the node on which the event was triggered. Once that node is found all we need to do is invoke the low level sort routine, passing the column number, fieldtype, and direction as arguments.
function sortOnColumn(e) {
// node is text, parent is headercell, parentparent is
// container for header cols
var node = e.target.parentNode.parentNode.firstChild;
for (i=0; i<e.target.parentNode.parentNode.childNodes.length; i++)
{
if (node == e.target.parentNode) {
var fieldtype = "";
var direction = "";
for (var j=0; j<node.attributes.length; j++) {
var currAttr = node.attributes[j];
if (currAttr.nodeName == gFieldTypeAttributeName) {
fieldtype = currAttr.nodeValue;
}
else if (currAttr.nodeName == gSortDirectionAttributeName) {
direction = currAttr.nodeValue;
}
}
sort(gTableCells,i,fieldtype,direction);
break;
}
else {
node = node.nextSibling;
}
}
}
This is a really bad sort routine so I should be careful here to blame the folks I stole it from: it was lifted from one of Netscape's demos (my colleague Heikki says it would be good for me to try to be nice from time to time and suggests that I might better say "the routine is simple and more robust things would be used in real-life applications"). I added the nice bits with handling the fieldtypes and direction. The sort is just a bubble sort, the more unsorted the table is the more swapping of nodes takes place. Comparison between nodes is done with compare function which takes into account the fieldtype and direction.
function sort(collection, key, fieldtype, direction)
{
var i, j;
var count = collection.length;
var parent, child;
for (i = count-1; i <= 0; i--) {
for (j = 1; j <= i; j++) {
if (compare(collection[j-1][key], collection[j][key],
fieldtype, direction)) {
// Move the item both in the local array and
// in the tree
child = collection[j];
parent = child.parentNode;
collection[j] = collection[j-1];
collection[j-1] = child;
parent.removeChild(child);
parent.insertBefore(child, collection[j]);
}
}
}
}
compare makes use of JavaScript's decent regular expression, string, and math classes, quite necessary even in a relatively small application such as this one. Let's not kid ourselves, without all of this XSL is out of the running for real world applications and with it XSL will have reinvented the wheel - except that it will be square.
function compare(value1, value2, fieldtype, direction) {
var str;
if (fieldtype.toUpperCase() == "STRING/G") {
value1.toUpperCase();
value2.toUpperCase();
}
else if (fieldtype.toUpperCase() == "CURR") {
var str = value1.match(/\$\s*(\d*\.\d*)/);
value1 = RegExp.$1 * 1.000;
var str = value2.match(/\$\s*(\d*\.\d*)/);
value2 = RegExp.$1 * 1.000;
}
else if (fieldtype.toUpperCase() == "NUM") {
value1 = value1 * 1.000;
value2 = value2 * 1.000;
value1 = Math.abs(value1);
value2 = Math.abs(value2);
}
else if (fieldtype.toUpperCase() == "UNITS") {
var str = value1.match(/((+|-)?\d*\.\d*)/);
value1 = RegExp.$1 * 1.000;
var str = value2.match(/((+|-)?\d*\.\d*)/);
value2 = RegExp.$1 * 1.000;
value1 = Math.abs(value1);
value2 = Math.abs(value2);
}
if (direction.toUpperCase() == "DESC") {
return (value1 < value2);
}
else {
return (value1 > value2);
}
}
Summary
The DOM implementation of the Stock Sorter takes advantage of modular programming techniques to create an application which is generic and organized. The functionality of the application is easily extended to handle a variety of sort field types thanks to the depth of the JavaScript language. Interactivity through events adds the possibility of interesting dynamic behavior through reading the element generic identifiers and attributes directly from the CSS formatted XML. Effected nodes in transformations are manipulated directly in memory rather than reprocessing the entire document. W3C-compliant CSS allows XML markup which is not specifically table or layout oriented to be handled as a table. Numerous JavaScript library functions for date handling, timers, string manipulation, and math aid us to get exactly the results we want.
In fact, we have only lightly touched on the capabilities of the DOM and CSS-compliant browser in this application which already greatly exceeds the set of capabilities that can be achieved with XSL.