4RDF: A Library for Web Metadata
October 11, 2000
| Table of Contents |
|
•Introduction to 4RDF |
4Suite is a library and collection of tools for XML and object database development using Python, with support for most UNIX flavors and Win32. Fourthought, Inc. develops 4Suite as open source software, and the package (this article discusses the 0.9.1 release) includes a set of sub-components:
- 4DOM: an XML/HTML library based on DOM Level 2;
- 4XPath: a complete XPath 1.0 engine;
- 4XSLT: a complete XSLT 1.0 processor;
- 4XPointer: a (so far) partial implementation of XPointer;
- 4ODS: an object persistence library based on ODMG 3.0, including a persistent DOM engine;
- 4RDF: a library based on the W3C RDF specifications.
There are other technologies supported in 4Suite, such as SAX and UUID generation, but the focus of this article is 4RDF. I shall assume familiarity with RDF. There are many resources providing introduction and discussion at the W3C's RDF page.
4RDF is a full-featured library based on the abstract models defined by W3C in their RDF Model and Syntax Recommendation 1.0 (RDF M&S) and RDF Schema Candidate Recommendation 1.0. (RDF Schemas). It provides several features beyond the RDF core, including multiple persistence mechanisms and an experimental inference layer for RDF data. Note that Fourthought is currently alpha-testing a 4Suite Server, a distribution of 4Suite with a built-in CORBA interface to allow use as a black box from other platforms and programming languages.
Introduction to 4RDF
Figure 1 shows a diagram of 4RDF's architecture. The core component is the RDF model. This provides an API for operations based on RDF M&S. The Model is a thin layer, for instance, it doesn't control how RDF data is stored: this is deferred to the driver. The driver provides a uniform interface so that many back-ends can be plugged in. 4RDF comes with the Memory back-end, which as its name implies, is very quick but provides no persistence. There is also support for PostgresQL and Oracle database storage.
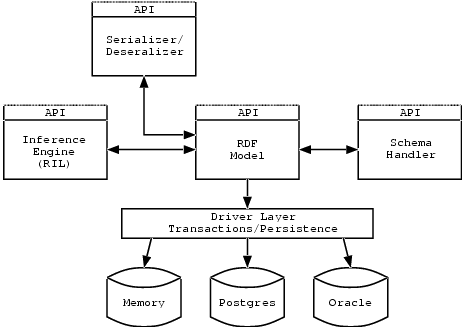
There is also a pluggable interface for serialization and deserialization of the RDF model. 4RDF comes with support (through DOM) for the XML serialization specified in RDF M&S. The SchemaHandler provides basic RDF Schema support. First of all, it can prep a model with all the RDF Schema classes and relationships from the spec. Then it can check model modifications against Schema constraints during processing.
Finally, there is an experimental inference engine that comes with 4RDF. It defines a special, open XML vocabulary known as RDF Inference Language (RIL) to perform expert-systems-like processing on RDF data with standard mappings between RDF predicates and the formal logic predicates more common in inferencing systems.
Basic Example
A small example will give you flavor of 4RDF and its features. Listing 1 is a Python program that reads in serialized RDF, performs some manipulations, and then prints out a serialization of the result. To get it running, see the packaging info. If you use the source package, the INSTALL file in the package should tell you how to set up. You don't have to be very familiar with Python to read and understand the example or to try out 4RDF yourself.
It will help to have Listing 1 available in another window as you read the next section.
The listing starts with a serialized RDF string. The RDF is actually an instance of RSS, describing an item from the Opentechnology.org site. (OpenTechnology.org is a site that Fourthought is working on as a way to gather discussions, comments, and other resources of value to the XML community as a dynamic knowledge base. There is strong emphasis on using XML tools such as XSLT and RDF so that people familiar with those technologies have a very free hand for customizing their view and use of the site. Please note that Opentechnology.org's RSS gateway is still in internal alpha, so treat this strictly as an example for now.)
In brief, for anyone unfamiliar with RSS, the RSS document describes a content channel: it first describes the basic channel, then an image that can be associated with the channel, and finally an item of content available on the channel. The descriptions give basic content access data such as title and URL.
The code then sets up the driver for the model. This provides the actual storage for the RDF data. In our example, we just use of the memory driver. Using the database drivers is similar. I also use the transaction features of 4RDF models, which aren't really meaningful using the memory driver, but they illustrate the feature. With a database backend, 4RDF helps manage the transactions for the developer. 4Suite server expands this with CORBA Object Transaction Service support.
Next, the code creates an RDF model instance itself, using the driver we created. Note that we give the model a base URI (the first parameter). This value might be the URI where the serialized version is available. It can also be an empty string.
Now we come to complete(), the heart of the 4RDF query engine. The
complete() method is a very basic pattern matching tool that returns all the
statements in the model whose parts are exactly the same as the given subject, predicate
and
object. None is used as a wildcard, so our first print statement, OUTPUT
1 in the listing, will return a list of all statements in the model. Of course since
we have a brand new model, it's empty.
Note that if we were using 4RDF's schema support (which is beyond the scope of this
article), the model would begin with statements representing all of the basic RDF
meta-model, such as statements describing rdfs:Class or
rdfs:Domain.
Next the code illustrates 4RDF's ability to read serialized RDF into a model. The
XML
serialization specified in RDF M&S is supported, including all abbreviations, but
excluding some problematic features such as aboutEachPrefix. Now that we have
read in our sample RSS data, the model contains all the corresponding statements,
as we see
when we print all the contents again (OUTPUT 2). A portion of OUTPUT 2
follows, indented for clarity.
[<RDF Statement at 135860888:
[Subject: http://opentechnology.org/rssgateway.rss,
Predicate: http://purl.org/rss/1.0/#title,
Object: "OpenTechnology.org"]>
<RDF Statement at 135829880:
[Subject: http://opentechnology.org/rssgateway.rss,
Predicate: http://purl.org/rss/1.0/#description,
Object: "An XML community site for threaded discussion and
knowledge management, using XML, DOM, XSLT, and RDF. "]>,
<RDF Statement at 135182912:
[Subject: http://opentechnology.org/rssgateway.rss,
Predicate: http://www.w3.org/1999/02/22-rdf-syntax-ns#type,
Object: "http://purl.org/rss/1.0/#channel"]>,
... ]
Next we illustrate a more selective complete(). It returns only the statements
with a predicate of "http://purl.org/rss/1.0/#title". OUTPUT 3 follows:
[<RDF Statement at 135182912:
[Subject: http://opentechnology.org/rssgateway.rss,
Predicate: http://purl.org/rss/1.0/#title,
Object: "OpenTechnology.org"]>,
<RDF Statement at 135862448:
[Subject: http://opentechnology.org/images/openlogo.gif,
Predicate: http://purl.org/rss/1.0/#title,
Object: "OpenTechnology.org Logo"]>,
<RDF Statement at 135831528:
[Subject: http://www.opentechnology.org/talk/view.html?
uri=urn:uuid:10a0b01-0-60b-a07-b090305f,
Predicate: http://purl.org/rss/1.0/#title,
Object: "RDF Inference Language (RIL)"]>]
Manipulating the Model
The contents of models can be manipulated directly from a program. The next part of
the
code solves the problem: "I'd like to remove all of the model that pertains to a particular
RSS item for OpenTechnology.org." It first does a complete() with the offending
item as the subject and all other parameters wildcards. It then iterates over all
the
resulting statements to remove them.
Finally, the code writes what's left of the model back into serialized form. Technically,
it creates a DOM (4DOM, to be exact) node representing the serialization. The code
then
finally uses 4DOM features to convert the resulting node to an XML string, print it
out
(OUTPUT 4), and then clean up. (Note that the ReleaseNode clean-up
is only required with Python 1.x, and as Python 2.0 is in beta this code will be unnecessary
before long.) OUTPUT 4 follows.
<?xml version='1.0' encoding='UTF-8'>
<rdf:RDF
xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:ns1='http://purl.org/rss/1.0/#'>
<rdf:Description
about='http://opentechnology.org/images/openlogo.gif'>
<ns1:link resource='http://opentechnology.org'/>
<ns1:title>OpenTechnology.org Logo</ns1:title>
<rdf:type resource='http://purl.org/rss/1.0/#image'/>
<ns1:inchannel
resource='http://opentechnology.org/rssgateway.rss'/>
<ns1:url resource='http://opentechnology.org/images/openlogo.gif'/>
</rdf:Description>
<rdf:Description about='http://opentechnology.org/rssgateway.rss'>
<rdf:type resource='http://purl.org/rss/1.0/#channel'/>
<ns1:title>OpenTechnology.org</ns1:title>
<ns1:description>
An XML community site for threaded discussion and knowledge
management, using XML, DOM, XSLT, and RDF.
</ns1:description>
</rdf:Description>
</rdf:RDF>
You can see that the description of the RSS item is gone: we removed it from the model.
Also note that 4RDF will not satisfy demands for strict round-tripping of RDF. First
of all,
the image and channel descriptions are transposed. Secondly, 4RDF generates automatic
prefixes for some output namespaces. This is correct and justifiable, but it might
be
annoying to some. Not as justifiable, however,, is some mangling of output URIs such
as
http://purl.org/rss/1.0/#image (notice the introduced "#"). This is a
recently discovered bug that will hopefully have been fixed by the time you read this.