XML Programming with C++
November 17, 1999
C++ is a popular programming language for which many XML related efforts already exist. The aim of this article is to introduce and analyze the different options available when using C++ for your XML applications.
We will examine two things: the main APIs and strategies for parsing and manipulating XML in your C++ application, and the practical uses and tradeoffs of approaches to XML parsing.
To get the most from this article, a basic understanding of the C++ language is required. Static model diagrams are illustrated in UML: the diagrams used show mainly inheritance and simple relationships and may not require previous UML knowledge. Nevertheless, we provide a basic UML guide containing all you need to know in order to understand the examples.
|
Contents |
|
•Part 1: XML Programming with C++ •Part 2: The SAX-based approach •Part 3: The Object Model-based approach •Part 4: Uses and Tradeoffs |
Different approaches to XML processing
Several toolkits and libraries have been produced for C++ based manipulation. Those toolkits mainly fall into two categories: event-driven processors and object model construction processors. We will examine both.
Event-driven approaches
In an event-driven approach for processing XML data, a parser reads the data and notifies specialized handlers that undertake the desired actions. Note that here the term event-driven means a process that calls specific handlers when the contents of the XML document are encountered. For instance, calling endDocument() when the end of the XML document is found.
The various XML parser implementations differ in their application program interfaces. For example, one parser could notify a handler of the start of an element, passing it only the name of the element and then requiring another call for the handling of attributes. Another parser could notify a handler when it finds the same start-element tag and pass it not only the name of the element, but a list of the attributes and values of that element.
Another important difference between XML parsers is in which representation they use to pass data from the parser to the application: e.g. one parser could use an STL list of strings, while another could use a specially made class to hold attributes and values. The methods for handling a start-element tag with each approach would be very different and would certainly affect how you program them.
// Example: different ways of communicating data to handlers
// STL based attribute passing
// with an STL based event-driven handler a startElementHandler
// method might look like this
virtual void HypotheticalHandler::startElementHandler
(const String name,const list<String> attributes) = 0;
// Special Attribute List Class provided
// With some event-driven APIs a special AttributeList object
// containing attribute information
// is used. This is the case with IBM's xml4c2 parser.
virtual void DocumentHandler::startElement(const XMLCh* const name,
AttributeList& attrs) = 0;
As you can see, the way processors notify applications about elements, attributes, character data, processing instructions and entities is parser-specific and can greatly influence the programming style behind the XML-related modules of your system.
Efforts to create a standard event-driven XML processing API have produced SAX (the Simple API for XML). A standard interface for SAX in C++ has not yet been developed. Nevertheless, the importance and growing use of SAX in C++ XML based applications is unquestionable, and makes it an important topic in our discussion.
In the next two sections, we examine the ideas behind both non-SAX and SAX-based event-driven approaches to parsing. For our examples, we will be using expatpp (C++ wrapper of James Clark's expat parser) and xml4c2 (IBM's C++ XML parser), respectively. IBM's parser will be re-released at the end of this year as "Xerces," part of the new Apache XML Project.
Non SAX event-driven approaches
Expat is a C parser developed and maintained by James Clark. It is event-driven, in the sense that it calls handlers as parts of the document are encountered by the parser. User-defined functions can be registered as handlers.
Here is a sample of a typical expat use in C:
/*
This is a simple demonstration of how to use expat. This program
reads an XML document from standard input and writes a line
with the name of each element to standard output, indenting
child elements by one tab stop more than their parent element.
[Taken from the standard expat distribution] */
#include <stdio.h>
#include "xmlparse.h"
void startElement
(void *userData, const char *name, const char **atts)
{
int i;
int *depthPtr = userData;
for (i = 0; i < *depthPtr; i++)
putchar('\t');
puts("I found the element:");
puts(name);
*depthPtr += 1;
}
void endElement(void *userData, const char *name)
{
int *depthPtr = userData;
*depthPtr -= 1;
}
int main()
{
char buf[BUFSIZ];
XML_Parser parser = XML_ParserCreate(NULL);
int done;
int depth = 0;
XML_SetUserData(parser, &depth);
XML_SetElementHandler(parser, startElement, endElement);
do {
size_t len = fread(buf, 1, sizeof(buf), stdin);
done = len < sizeof(buf);
if (!XML_Parse(parser, buf, len, done)) {
fprintf(stderr,
"%s at line %d\n",
XML_ErrorString(XML_GetErrorCode(parser)),
XML_GetCurrentLineNumber(parser));
return 1;
}
} while (!done);
XML_ParserFree(parser);
return 0;
}
This program simply shows the string "I found the element" followed by the element name for each element found. Note the existence of a void *userData parameter that expat uses to give you the possibility of managing your information across calls. In the previous example, the userData is employed to keep track of the indentation level that should be used when printing elements and attributes to the standard output.
Expat has many advantages: it is very fast and very portable. It is also under the GPL (the GNU General Public License), which means you can freely use and distribute it. But it is just plain C, so some strategy must be chosen in order to integrate it with your OO C++project.
One strategy would be simply to create global functions to register with expat. Those functions can receive a pointer to the data you want to modify while reading the file (e.g., a Count object that will store the number of characters in the file), and then all you have to do is register them with expat. This is a straightforward approach, but it brings several undesirable consequences into the picture:
-
It decreases the modularity of your program.
-
It makes your program less cohesive (i.e., related methods are not bundled together).
-
It may ruin your OO design on a fundamental level (e.g., XML serialization of your objects).
All of the above will probably result in a less-maintainable program with an error prone design. A better option would be to wrap expat using a C++ class that will encapsulate the C details and provide you with a clean list of methods that you can override to suit your particular needs. This is how wrappers like expatpp work.
Expatpp is a C++ wrapper for expat. It was developed by Andy Dent with this basic idea: the constructor of expatpp creates an instance of an expat parser, and registers dummy functions as handlers that call the corresponding expatpp override-able methods.
Some code will make things clearer:
// In its class definition, expatpp declares the callbacks
// that it will register with the parser:
static void startElementCallback
(void *userData, const XML_Char*
name, const XML_Char** atts);
static void endElementCallback
(void *userData, const XML_Char* name);
static void charDataCallback(void *userData, const XML_Char* s,
int len);
//... and so on for the other handlers like
// processingInstructionCallback
// At the constructor, expatpp creates an expat parser and registers
// the callbacks
expatpp::expatpp()
{
mParser = XML_ParserCreate(0);
XML_SetUserData(mParser, this); //Note that the user data is
//the object itself
XML_SetElementHandler(mParser, startElementCallback,
endElementCallback);
XML_SetCharacterDataHandler(mParser, charDataCallback);
//... and so on with the other callbacks
}
// Now, for each callback there is a partner override-able member
// like
virtual void startElement(const XML_Char* name, const
XML_Char** atts){
// Note that the default behavior is to do nothing. In your
// derived class you can override this and for example print
// the name of the element like
// count << name;
}
// All a callback does is to call its partner method
inline void
expatpp::startElementCallback
(void *userData, const XML_Char* name,
const XML_Char** atts)
{
((expatpp*)userData)->startElement(name, atts);
}
// In runtime, when the parser begins calling the callback, the
// appropriate method overridden in your derived class will be
// called. For the complete code look at expatpp.[h|c]
As you can see, the userData is used to maintain a pointer to your expatpp object. When the object is constructed, the callbacks are registered as handlers to expat. When parsing events occur, the handlers call the appropriate methods in the class. The default behavior of these methods is to do nothing, but you can override them for your own purposes.
expatpp interface
The expatpp interface defines wrappers for all the methods in expat and includes the following members:
virtual void startElement
(const XML_Char* name, const XML_Char** atts);
virtual void endElement(const XML_Char* name);
virtual void charData(const XML_Char *s, int len);
virtual void processingInstruction(const XML_Char* target, const
XML_Char* data);
virtual void defaultHandler(const XML_Char *s, int len);
virtual void unparsedEntityDecl(const XML_Char *entityName, const
XML_Char* base, const XML_Char* systemId,
const XML_Char* publicId,
const XML_Char* notationName);
virtual void notationDecl(const XML_Char* notationName, const
XML_Char* base, const XML_Char* systemId,
const XML_Char* publicId);
// XML interfaces
int XMLPARSEAPI XML_Parse
(const char *s, int len, int isFinal);
XML_Error XMLPARSEAPI XML_GetErrorCode();
int XMLPARSEAPI XML_GetCurrentLineNumber();
This interface defines a handler base for expatpp (look at the source code for details). Along with the example included below, it should be enough to get you started with expatpp in an XML project.
expatpp sample
The following example uses expatpp to create a tree view of the elements of the document. Unlike the rest of the examples in this article, this particular program was constructed using Inprise C++ builder, and depends on it.
// We declare a handler that will be capable of
// constructing the tree. In order to do so it will override
// the startElement and endElement methods (the others can
// be ignored)
// [from myParser.h]
class myParser : public dexpatpp
{
private:
TTreeView *mTreeView;
// The tree view in which the elements will be shown
TTreeNode *lastNode;
public:
inline myParser(TTreeView *treeToUse);
inline void startElement
(const XML_Char* name, const XML_Char** atts);
inline void endElement(const XML_Char* name);
};
// Now, for the implementation, all we have to do is
inline
void myParser::startElement
(const XML_Char* name, const XML_Char** atts)
{
lastNode = mTreeView->Items->AddChild(lastNode, name);
}
// and
inline
void myParser::endElement(const XML_Char* name)
{
lastNode = lastNode->Parent;
}
For the complete, and more verbosely documented, code, download this file: expatppExample.zip. When given an XML file, the application will produce something like this:

The same approach can be, and has been, used for wrapping other C parsers for use in C++ code. These other parsers include, most notably, the Gnome Project libxml parser by Daniel Veillard.
The next section will cover the Simple API for XML—SAX.
SAX event-driven approaches
|
Contents |
|
•Part 1:
XML Programming with C++ |
The Simple API for XML, SAX, is an event-driven API for parsing XML documents. It defines several handler classes that encapsulate the methods needed for specific tasks when parsing XML documents, such as external entity handling. As with other event-driven parsers, the basic process for the definition of an XML module in your project may be described by the following steps:
-
Subclass the required handler base classes. (In the previous section you did so only from expatpp; now you have more classes available for subclassing, which we will explore below.)
-
Override the desired methods.
-
Register your handler with the parser.
-
Start parsing.
These steps can be seen in the following example which prints an XML file, keeping track of the correct indentation. The interfaces used are explained further below. You can also look at the SAXCount example from IBM's xml4c2 documentation.
// We declare a handler of our own that will be capable of
// remembering the correct indentation for "pretty"
// printing the file. In order to do so we override
// the startElement, characters and endElement handlers.
// Take time to compare this solution to the expatpp solution to
// the same problem (above)
void PrettyPrint::startElement(const XMLCh* const name,
AttributeList& attributes)
{
indent++; // A new element started, it should be indented one
// level further than the current level
int i;
for(i = 0; i < indent; i++)
outStrm << "\t";
outStrm << "<" << name;
unsigned int len = attributes.getLength();
for (unsigned int i = 0; i < len; i++)
{
outStrm << " " << attributes.getName(i)
<< "=\"" << attributes.getValue(i) << "\"";
}
outStrm << ">";
}
void PrettyPrint::endElement(const XMLCh* const name)
{
int i;
for(i = 0; i < indent; i++)
outStrm << "\t";
outStrm << "</" << name << ">";
indent--;
}
void PrettyPrint::characters(const XMLCh* const chars,
const unsigned int length)
{
for (unsigned int index = 0; index < length; index++)
{
switch (chars[index])
{
case chAmpersand :
outStrm << "&";
break;
case chOpenAngle :
outStrm << "<";
break;
case chCloseAngle:
outStrm << ">";
break;
case chDoubleQuote :
outStrm << """;
break;
default:
outStrm << chars[index];
break;
}
}
}
void PrettyPrint::processingInstruction(const XMLCh* const target,
const XMLCh* const data)
{
int i;
for(i = 0; i < indent; i++)
outStrm << "\t";
outStrm << "<?" << target;
if (data)
outStrm << " " << data;
outStrm << "?>\n";
}
Download the full source here: saxExample.zip.
What makes SAX important is not the idea behind the parsing—the essence of the event-driven approach is the same as with expatpp or any other event-oriented parser—but the standardization of the interfaces and classes that are used to communicate with the application during the parsing process.
These classes and interfaces (abstract classes in C++) are divided thus:
-
Classes implemented by the parser: Parser, AttributeList, Locator (optional class used to track the location of an event)
-
Classes implemented by the application: DocumentHandler (very important—this is the one you will subclass in nearly all applications), ErrorHandler, DTDHandler, EntityResolver.
-
Standard SAX classes: InputSource, SAXException, SAXParseException and HandlerBase. (This might be your starting point in many applications since it inherits from all the handlers, providing default behavior for all non-overriden methods.)
SAX was initially developed for Java, but it has been ported to other languages like Python, Perl and C++. In C++, you have several representations and strategies to choose from when porting the original SAX API. Since there is no common C++ SAX interface, the different implementations might have some small, and not-so-small, differences.
In this article, we'll stick with IBM's xml4c2 SAX implementation. In order to write your own XML modules, you will need to inherit from the application classes of the API and override the methods you want to perform special actions.
Here is an overview of the handlers you will inherit from, a more complete documentation of them can be found with the xml4c2 distribution.
| Handler | Description |
|---|---|
| DocumentHandler | This is the main interface that SAX applications implement. It defines methods to let the parser inform the application about basic parsing events. In order to use it, the application should use a class that implements DocumentHandler and then register an instance with the parser, which will later feed it with the appropriate events. |
| ErrorHandler | This interface is provided in order to allow the SAX application to implement customized error handling. It is registered using the setErrorHandler method. The parser will then report all errors and warnings through this interface. |
| DTDHandler | Objects of a class that implement the DTDHandler interface receive information about notations and unparsed entities. They are registered using the parser's setDTDHandler method. |
| EntityResolver (less commonly used) | If the application needs to intercept any external entities before their inclusion, it must make use of a class that implements this interface registering it via the setEntityResolver method. Any external entities (including the external DTD subset and external parameter entities) will be reported through it. |
Note that by making use of the multiple inheritance support of C++, a user-defined handler can implement several of those functions (e.g., error handling and document handling).
// ...
class MyHandler : public DocumentHandler, ErrorHandler
// ...
parser = new NonValidatingSAXParser;
MyHandler* handler = new MyHandler();
parser->setDocumentHandler(handler);
parser->setErrorHandler(handler);
The XML part of your application will probably take the following form:

If you are familiar with patterns, you will see this is similar to a simple Builder Pattern, i.e., we detach the XML responsibility from the client objects and delegate it to a collection of objects (the parser itself and your handlers) that will know how to incrementally construct some product. For a complete description of the Builder pattern see the book "Design Patterns" by Gamma et al. ("The Gang of Four.")
Note that this product can be expressed as another object, a simple return value, or even as some transformation of the attributes of your handler object.
This concludes the SAX review, and can serve as a starting point for your C++ XML modules. Please review the documentation of your chosen implementation for further examples. IBM's xml4c2 is recommended because of its comprehensive documentation.
Object model approaches
|
Contents |
|
•Part 1:
XML Programming with C++ |
The previous section presented the event-driven approach to handling XML documents. There is another option for the handling of XML documents: the "object model" approach. This approach is also known as the "tree based approach," and it is based on the idea of parsing the whole document and constructing an object representation of it in memory.
There is a standard language independent specification, written in OMG's IDL, for the constructed object model. It is called the Document Object Model, or DOM.
DOM
The next section presents the basic ideas behind the DOM, and the typical steps involved when writing a XML DOM-based module in your C++ application.
Expressing a document as a structure and making it available to the application is not new: all major browsers have done so for years in their own proprietary way. The important idea behind the XML DOM is that it standardizes the model to use when representing any XML document in memory. DOM-based C++ parsers produce a DOM representation of the document instead of informing the application when they encounter elements, attributes etc.
The Document Object Model is a language- and platform-independent interface that allows programs and scripts to dynamically access and update the content structure and style of documents. There is a core set of interfaces that every DOM 1.0-compliant implementation must provide. Here we concentrate on those core interfaces. Currently, anything in a document can be accessed using the DOM (1.0), except for the internal and external DTD subsets, for which no API currently exists.
The DOM, as the name implies, is an object model as opposed to a data model.
The object-oriented interfaces define the semantics of a structural model, independently of the implementation chosen for it. That means that DOM parser implementations are free to choose whatever internal representation they like, as long as they comply with the DOM interfaces. The next section will show the basic DOM core interfaces; then we will look at the steps you will use with the DOM approach.
DOM Interfaces
The DOM level 1 core defines a basic set of interfaces that allow the manipulation of XML documents. It provides methods for the access and population of the document. These methods are encapsulated in two sets of interfaces: the fundamental core interfaces and the extended interfaces.
Here is a basic presentation of the main interfaces. For a complete description and all the methods, you will need to download a DOM library. Again, xml4c2 is a good choice because of its excellent documentation.
Fundamental Interfaces
| Interface | Description |
|---|---|
| Node | This interface is the primary datatype for the entire Document Object Model. It represents a single node in the document tree. This is the base interface for everything in the model—therefore all objects implementing the Node interface expose the methods defined by it. One should be careful about this because some derivatives of node, like the text node, expose some Node methods they don't really support like "get children," which results in an exception since a text node cannot have children. |
| Document | Class to refer to XML Document nodes in the DOM. Conceptually, a DOM document node is the root of the document tree, and provides the primary access to the document's data. |
| DocumentFragment | DocumentFragment is a "lightweight" Document object. This object encapsulates a portion of the document, which is very useful in applications that need to rearrange or modify portions of the tree, for example an editor doing a cut/paste. Note that the fragment contained is not (necessarily or even often) a valid XML document. |
| Element |
The majority of objects, apart from text, that one may find in the DOM Tree are DOM Element nodes. They represent elements in the document object model, and since they can have other Element nodes as children, their structure reflects the arrangement of the original XML document. |
| Other fundamental interfaces |
The rest of the fundamental interfaces are: DOMImplementation, NodeList, NamedNodeMap, CharacterData, DOMException (which in IDL is not an interface but an exception), Attr, Text, Comment. Again, for more details on these, you are encouraged to download the complete documentation included in toolkits like xml4c2. |
Extended Interfaces
The extended interfaces also form part of the core DOM. These interfaces are:
-
CDATASection
-
DocumentType
-
EntityReference
-
ProcessingInstruction
Important details about DOM level 1
In order to get a complete view of the DOM, you should read the W3C recommendation. Nevertheless, here are some important points to keep in mind:
Limitations of Level 1
DOM Level 1 is strictly limited to those methods needed to represent and manipulate the document structure. At the time of the writing of this article DOM level 2 was not yet endorsed as a W3C Recommendation, and no C++ implementation was available, so for the sake of usability, I decided to focus on DOM level 1. Future DOM levels may provide:
-
Thread safety
-
Events
-
Control for rendering via stylesheets
-
Access control
Persistence
Saving the DOM representation is left to the implementation
Repercussions of changes to nodes
Changes to a Node are reflected in any NodeList or NamedNodeMap that refer to them. (This translates to the use of references or pointers in your C++ implementation.)
Memory management
The DOM API is memory-management-philosophy independent (i.e., the recommendation does not specify any memory management policy). This is the responsibility of the implementation.
DOMString type
DOM defines the DOMString type in IDL as
typedef sequence<unsigned short> DOMString;
That is, a sequence of 16 bit characters using the UTF-16 encoding.
Case sensitivity
Even though some HTML processors may expect normalization to uppercase, the DOM bases its string matching in a purely case sensitive way. Nevertheless, it is admitted by the recommendation that some normalizations may occur before DOM construction.
The basic structure of an XML DOM-based module
In contrast to the role of the application during event-based parsing, the focus of the activity in a DOM-based application is post-parsing. The basic layout of an XML module using DOM might look something like this:

Here the main XML application class is no longer a handler but a manipulator of the DOM representation produced. Note that this is an important change of focus: your application's processing is no longer done at parsing time but rather in an extra module that will manipulate nodes.
The basic steps for the creation of your XML module would be:
-
Create and register handlers for errors and other implementation-dependent activities.
-
Create a DOM manipulator that will have the responsibility of (1) issuing parsing requests to the parser (2) manipulating the results of such requests.
-
Include the necessary manipulator/rest of the application interaction.
In order to complete the picture and give you a real idea of how all this fits together, the best thing to do is a complete walk-through of an example DOM-based implementation. Again, we consider an XML "pretty printer" as an example. A full example can be found in the DOMPrint sample distributed with IBM's xml4c2.
Note that for bigger projects, the correct encapsulation of the DOM processing activities in the above scheme is meant to keep your design clean and your program manageable.
The translation of the DOMPrint example to the DOM manipulator/DOM Parser/Rest of the application scheme is left as a simple exercise for the reader. In this case, all it requires is to take the methods of the original and encapsulate them in a class. So the main function can be something like:
#include "DOMBeautifier.h"
static char* xmlFile = 0; // The name of the file to parse
// --------------------------------------------------------------
// Main - very simplified version -- for guidance purposes only.
// Note that the main no longer takes responsibility of creating
// the parser or printing the file. Try encapsulating that
// in the DOMBeautifier class yourself, based on the original
// DOM_Print (it's very easy an will give you a better feeling
// of the library)
// --------------------------------------------------------------
int main(int argC, char* argV[])
{
// Check command line and extract arguments.
if (argC != 2)
return 1;
// The first parameter must be the file name
xmlFile = argV[1];
// Now initialize the XML4C2 platform
try {
XMLPlatformUtils::Initialize();
}
catch(const XMLException& toCatch) {
return 1;
}
DomBeautifier *myBeautifier = new DomBeautifier();
if(myBeautifier->Beautify(xmlFile) == ERRORS){
return 2;
}
// Cleanup
delete myBeautifier;
return 0;
}
Now that we have seen both the event-based and DOM approaches to C++ XML document handling, we will examine the different considerations that will help you decide between each approach.
Uses and Tradeoffs
|
Contents |
|
•Part 1:
XML Programming with C++ |
In this section, uses of and tradeoffs between the event-based and object model approaches will be discussed. In particular, three topics will be examined: having XML-aware objects that can be used as handlers, using factories to create/modify objects, and having a document-centered application. The section concludes with a list of C++ parsers and their suitability for the purposes outlined.
Note that the designs outlined here, while useful and used in real applications, are not necessarily the best ones for your project. They are provided only as a guide.
XML-aware objects used as handlers
The first form of XML modules your application might use are simple XML aware classes designed to be registered in an event-driven parser. These classes are characterized not only by their handler nature, but by the self-containment of their activities. Their use doesn't usually compromise other classes, and the parsing of an XML document will often result in a change in their attributes or output operations.
These classes will take the following simple form:
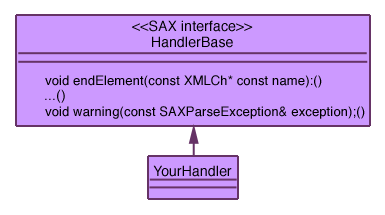
Note that the handler base your handler inherits from is not necessarily HandlerBase from SAX; we use the term because every C++ event-driven parser will provide such base classes with a default behavior (HandlerBase in the case of xml4c2 or SAXParser, and expatpp itself in the case of expatpp).
Numerous examples of this approach are found with every parser, and they constitute the simplest, though very useful, form of XML use. Among the typical examples are the counting of elements in a document and the printing of each document element as it is found. Our SAX pretty printing example is good example of this approach.
These example activities could also be performed by traversing the object representation of the document, but they are typically done by the event-driven method because it does not require the memory expenditure that creating the object representation would.
There are lazy ways of creating the DOM in order to minimize the memory consumption, but even so in general terms, the event-driven approach must be used in these traversal cases for the sake of simplicity and good use of memory resources.
Factories for the creation or modification of other objects
The next typical scenario is the definition of factory classes for the manipulation of other objects according to the information in the XML document. These classes will usually take the following form:
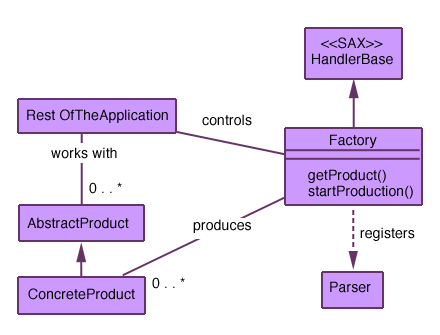
The first of such manipulations that comes to mind is serialization. The process of making an object persistent using XML is a very important issue that can be handled this way. The responsibility of saving the object as XML could also be in the object itself, but this approach—abstracting the responsibility for serialization—is often preferred.
Many other uses for this approach can be found. A simple example would be the manipulation of a collection of objects in accordance with XML-encoded instructions sent by a remote object, for example, a collection like:
map<name, long, less<string>> directory;
// A simple STL directory using an associative container map
// That will hold names(the keys) and phone numbers(the longs
// that serve as values for that keys)
// the third parameter less<string> is a function object
// used to compare two keys.
could be manipulated by a remote object by sending messages like
<changeNumber name="Borges">5716124469</changeNumber>
to our factory that would translate them to:
directory["Borges"] = 5716124469;
Again, as in the simpler handlers described above, the preferred approach for these factories is the event-driven one, since it doesn't involve the cost of keeping the document in memory.
Of course, there are many special cases that must be considered. Take the case of an object that must answer questions from other objects about a particular document (like "is there any element named H1?"). In this case a tradeoff between memory consumption and speed takes place, since both a DOM and an event-driven approach could be used. The first involves more memory consumption but will greatly speed the searches of specific elements in the document. The second will consume no memory representing the document but will require a O(n) complexity over the XML document on disk for each search. The final decision will have to take into consideration the amount of requests, the size of the documents, and the amount of available resources.
So far, we have reviewed two mainly event-driven uses. In the next section we will explore cases where DOM is a more natural option.
Document-centered applications
The uses of the DOM can be very varied, such as exposing an object model of the document in a browser so an extension language can be used to manipulate the document. We will concentrate on a general case: the use of DOM as the model in a Model-View-Controller scheme.
Using DOM in a Model View Controller (MVC)
Basically, the MVC defines a structure where there is an underlying model, several views that reflect the state of the model, and a controller that receives requests to change the model. It also ensures that these changes are reported to the views.
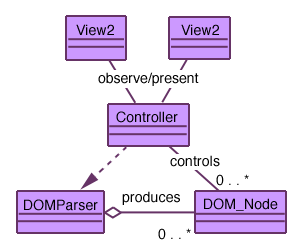
This is the case in many document-centered applications. For example, take a simple application that reads a document containing a memo like this:
<?xml version="1.0"?>
<header>
<to>Panda</to>
<from>Le roi sanche</from>
</header>
...and shows it to the user allowing it to be edited and written back to a file.
This, like any other application that needs to manipulate an object representation of the document itself as a base model, is perfect for DOM use.
Refinements to the model of constructing the tree and modifying the DOM via direct calls to the API can be used. Real life view objects can issue command objects that include the document fragment that is the target of the change (instead of changing the DOM directly). Also, several strategies to avoid loading the whole document at once could be applied.
Nevertheless, the basic idea remains what our simple example tries to show: whenever you need to manipulate the document directly as your model (instead of constructed domain-specific objects), DOM constitutes the natural choice.
Widely used parsers
We finish this section by presenting a list of commonly used C++ parsers and their basic information. (For performance comparisons, please refer to Benchmarking XML Parsers.)
| Parser | DOM Support | SAX Support | Platforms supported | Validation support | Download from |
|---|---|---|---|---|---|
| libxml | YES | YES | Linux, Win32 (possibly many others) | YES | ftp://rpmfind.net |
| expat (C) | NO | NO | Win32, Unix, and practically everywhere a modern C compiler exists. | NO | ftp://ftp.jclark.com |
| expatpp (only the wrapper, without extensions) | NO | NO | Win32, Linux, Mac (and many untested others) | NO | ftp://ftp.highway1.com |
| xml4c2 | YES | YES | IBM platforms: AIX 4.1.4 and higher, Win32 (MSVC 5.0, 6.0 compilers), Solaris 2.6, HP-UX B10.2 (aCC and CC), HP-UX B11 (aCC and CC), Linux | YES | www.alphaworks.ibm.com |
As you can see, C++ is well suited for XML processing in terms of availability, size and complexity of code, conformance, and even to a great extent, portability—not to mention performance. There is nothing especially better about using other languages like Java for XML programming.
All languages have strengths and weaknesses that should be taken into consideration when choosing the language to use for your project. It may be true that C++ has a steeper learning curve, and perhaps C++ programmers can be a little harder to find, but those considerations have nothing to do with C++'s ability to process XML. Great care should be taken when facing marketing hype about supposedly "perfect marriages" between a language and a specific technology. XML is no exception.