An Introduction to XProc 3.0
November 5, 2019
Table of Contents
Introduction
XProc is an XML based programming language for processing documents in pipelines: chaining conversions and other steps together to achieve the desired results. It has been around in its 1.0 version since 2010.
In 2017 a group of people (editorial team: Achim Berndzen, Gerrit Imsieke, Norman Walsh and Erik Siegel) started working on a 3.0 version (2.0 was skipped for several reasons). The syntax was simplified and new features added. Underlying standards, most notably XPath, were updated to their latest versions. A programmer's reference book is in the making.
In November 2019, when this article was written, we were nearly there. The planning is to finish the standard around the end of 2019. Documentation and processors that allow you to better understand and, most importantly, run it should arrive somewhere in the beginning of 2020. The language definition itself (http://spec.xproc.org/) is almost finished and can be, apart from some minor details, considered stable. At the end of this article you'll find a list of references to further information.
This article is the first of a planned series on XProc. It contains an introduction to XProc and its main concepts.
What is XProc?
Let’s try to answer this question with an overview of XProc’s main high-level characteristics first:
XProc is a programming language, expressed in XML, in which you can write pipelines.
An XProc pipeline takes data as its input (often XML) and passes this through specialized steps to produce end results.
Steps range from simple ones, like reading and writing data, to more complex stuff like splitting/combining/pruning, transformations with XSLT and XQuery, validations against schemas, etc.
Within a pipeline you can do things like working with variables, branching, looping, catch errors, etc. Everything is based on the data flowing through.
XProc pipelines are not limited to a linear succession of steps. They can fork and merge.
XProc allows you to create custom steps by combining other steps. These custom steps can be used just like any other. Custom steps can be collected into libraries.
XProc aids in the housekeeping surrounding the processing, like inspecting directories, reading documents from zip files, writing things to disk, etc
There is software that can execute these pipelines, the so-called XProc processors.
Now why and when would this be useful? In the physical world, pipelining and working in specialized steps is not unusual. Take for instance an oil refinery: it takes crude oil as its input and, through a series of steps and intermediate products, produces petrol/gasoline, kerosene, diesel, etc. Just one look shows that refineries take the word “pipeline” very literal…
A classic from the IT world are of course UNIX pipelines. Some command produces some
output and we do further processing (by, for instance, grep or tail
or head) to get the information needed. The character used for chaining steps,
|, is even called the "pipe" character!
So why would we do this in the world of information and document processing? One of the main reasons is that data is often not in the format we need it to be. Some examples:
We have XML coming from some data source but need HTML for our website.
Multiple weather stations produce data that needs to be merged into a single consolidated view. From this we produce a map with the information nicely laid out.
Word processors produce zip files with lots of XML documents inside (most word processors do nowadays). You need the text in some other format so you’ll have to inspect the zip file, combine the XML documents inside and transform the result into what you want.
For straight transformation of XML data there are languages available, like XSLT and XQuery. But more often than not tasks are more complex than can be done in a single transformation: chaining, splitting and merging comes into play. Surrounding the transformations you need housekeeping, like where to read from or write to, inspect directories and zip files and write logs. Also from a software engineering point of view it is often desirable to work in smaller steps to get more legible and better maintainable code. This is where XProc comes into play: a single executable language to express this.
A first example
As a relatively simple first example, consider the following use-case: an off-the-shelf web-shop application produces some very verbose XML document that contains order data. The data itself is complete (everything we need is in there) but its format, its representation, is not directly usable. Since it is XML we cannot send it to the customer as an invoice. For this purpose we need to convert it first. We also want to feed the accounting system with the order information but this uses a completely different XML format…
So we take the very verbose web-shop XML document and:
Filter the verbose input document into something smaller and more to the point.
Take the filtered output and create the XML for feeding the accounting system.
Create an XHTML version of the invoice for display on the customer portal of the website.
Create from the XHTML a PDF version of this same invoice for e-mailing it to the customer. This is done by first transforming it into XSL-FO (an XML standard for describing paged media) and transform this into PDF.
In this example all the heavy work, the transformations themselves, will be done by XSLT, which we won't show. We'll concentrate on how the XProc pipeline looks like. Schematically:
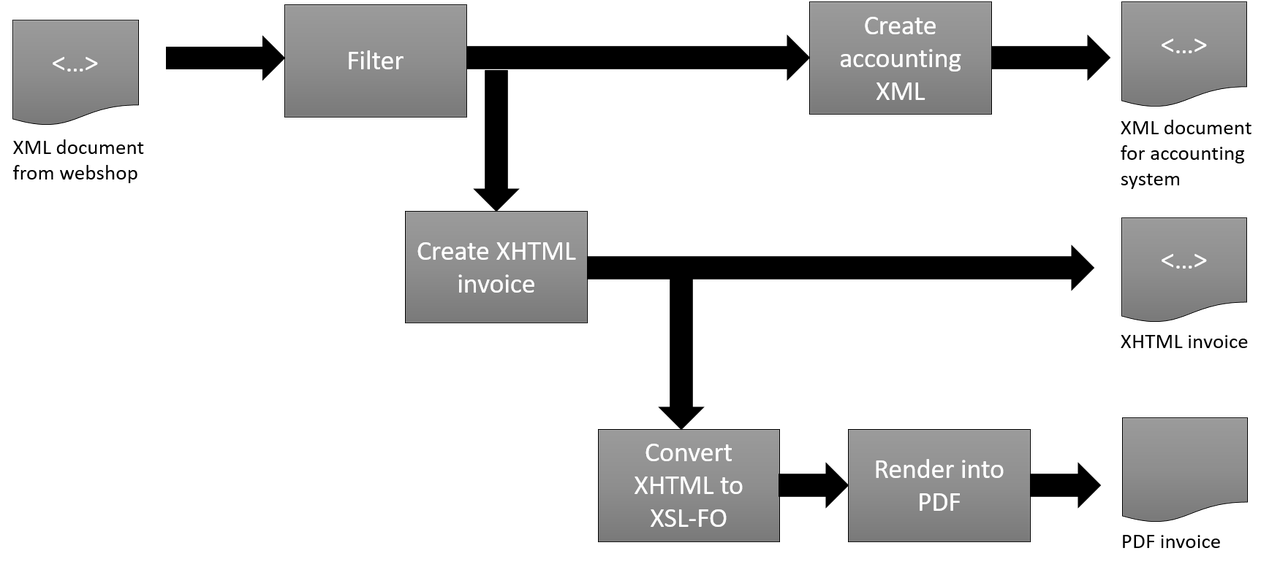
And this is how it could be expressed in XProc:
Example 1. The example pipeline, expressed in XProc
<p:declare-step xmlns:p="http://www.w3.org/ns/xproc" version="3.0">
<!-- ================================================================== -->
<!-- PROLOG: -->
<p:input port="source" primary="true">
<p:documentation>This is where the XML document from the webshop
comes in</p:documentation>
</p:input>
<p:output port="result" primary="true" pipe="result@create-accounting-xml">
<p:documentation>Our primary output will be the XML document for the
accounting system</p:documentation>
</p:output>
<p:output port="xhtml-invoice" primary="true" pipe="result@create-xhtml-invoice">
<p:documentation>This is where our XHTML invoice will come out</p:documentation>
</p:output>
<p:option name="pdf-filename" required="true">
<p:documentation>This is the location where we'll write the PDF version
of the invoice</p:documentation>
</p:option>
<!-- ================================================================== -->
<!-- BODY: -->
<p:xslt name="filter-input">
<p:with-input port="stylesheet" href="path/to/filter-webshop-xml.xsl"/>
</p:xslt>
<p:xslt name="create-accounting-xml">
<p:with-input port="stylesheet" href="path/to/create-accounting-system-xml.xsl"/>
</p:xslt>
<!-- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -->
<!-- subpipeline for creating the XHTML invoice: -->
<p:xslt name="create-xhtml-invoice">
<p:with-input port="source" pipe="result@filter-input"/>
<p:with-input port="stylesheet" href="path/to/create-xhtml-invoice.xsl"/>
</p:xslt>
<!-- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -->
<!-- subpipeline for creating the PDF invoice: -->
<p:xslt name="create-fo-invoice">
<p:with-input port="stylesheet" href="path/to/create-xsl-fo-from-xhtml.xsl"/>
</p:xslt>
<p:xsl-formatter/>
<p:store href="{$pdf-filename}"/>
</p:declare-step>
As in every programming language, this is certainly not the only way to write this. Syntax variations are possible.
XProc Fundamentals
Pipelines or Steps?
XProc is a pipeline language. A pipeline is something that takes documents as input(s), does something with them using a series of steps, and produces output(s). For example:

Steps are the building blocks of XProc. A step takes documents as input(s), does something with the data flowing through and produces output(s). Now that sounds suspiciously familiar, doesn’t it? Indeed: on the outside a step and a pipeline are indistinguishable. There is input, output and document processing being done. If you don’t know what’s inside and consider the thing a black box, you wouldn’t know the difference.
And that’s exactly how XProc treats the two concepts: a pipeline is a step and steps are the XProc building blocks. Once you’ve written a pipeline you can use it as a step somewhere else, just like any of the standard built-in steps. Within XProc, pipeline and step are interchangeable terms.
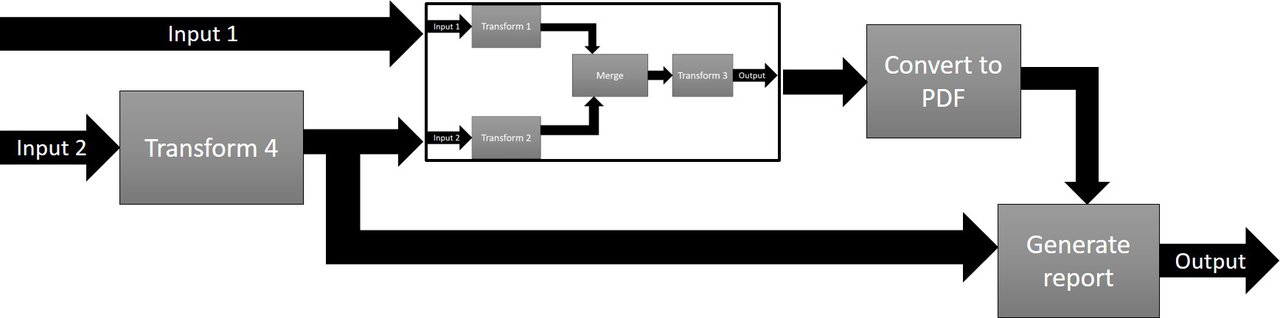
Documents
Flowing through XProc's veins are documents. And although XProc is XML based and comes from an XML background, the 3.0 version can handle any kind of document. The standard distinguishes five main document types:
- XML
Given its origin its no surprise that XML is a first class citizen of the XProc world. Most of its functionality is for manipulating XML.
It's probably good to realize that XML documents do not flow through the pipelines as those "text documents with lots of angle brackets", nor are they read from or written to disk in between steps. How it's done exactly is up to the language processor, but you can be sure they flow through as highly optimized data structures, in memory (as long as it fits). This makes processing XML with XProc much more efficient than using, for instance, batch/shell scripts or
make, as is often done.- HTML
HTML documents flow through XProc as XML documents. The difference is when they are read from or written to disk: special HTML handling rules apply.
- JSON
Yes, albeit a certain animosity between the XML and the JSON world, XProc can absolutely handle JSON. It flows through the pipelines as queryable and manipulatable data structures.
- Text
Text flows through as… text. There are some specialized steps to manipulate it. Or you can use XSLT or XQuery to crunch/create/change it.
- Others
XProc can also handle other (a.k.a. binary) document types, like JPEG or ZIP files. There aren't many standard steps available to work with them. A notably exception is archive handling (e.g. ZIP files). Archives can be queried, extracted and constructed. Some language processors might in the future implement processor-dependent specialized steps for binary document types.
An interesting feature of XProc document handling is that not only the contents, the representation, of the document flows through. Every document will be accompanied by properties: a set of name/value pairs. XProc uses some of these properties for its own purposes (for instance to hold the document's base URI and its MIME type) but you can add your own. Properties can be inspected and modified by the XProc pipeline.
Steps
XProc's main building blocks are steps. You chain steps together to create bigger, more complicated steps, a.k.a. pipelines. Let's have a look at their main properties:
- Type
All steps have a type. Its analogous to the name of a function, method or procedure in other programming languages. For instance the step with type
p:xsltperforms an XSLT transformation,p:insertinserts one piece of XML inside another, etc.To invoke a step in your pipeline you use the type as the name of the element. For instance, this pipeline invokes an XSLT transformation using the
p:xsltstep:Example 2. Invoking an XSLT transformation using the
p:xsltstep<p:declare-step xmlns:p="http://www.w3.org/ns/xproc" …> … <p:xslt> … </p:xslt> … </p:declare-step>
- Ports
Ports are the connectors of a step, where documents flow in (input ports) or out (output ports). Ports are the equivalent of the USB connectors on your computer or the network connectors on your router.
A port must have a name. You use this name to address the port in your pipeline.
- Options
Steps can have options. Options are name/value pairs that can be used to further determine a step's functionality.
As an example let's have a look at p:insert. This step inserts one XML document into another.
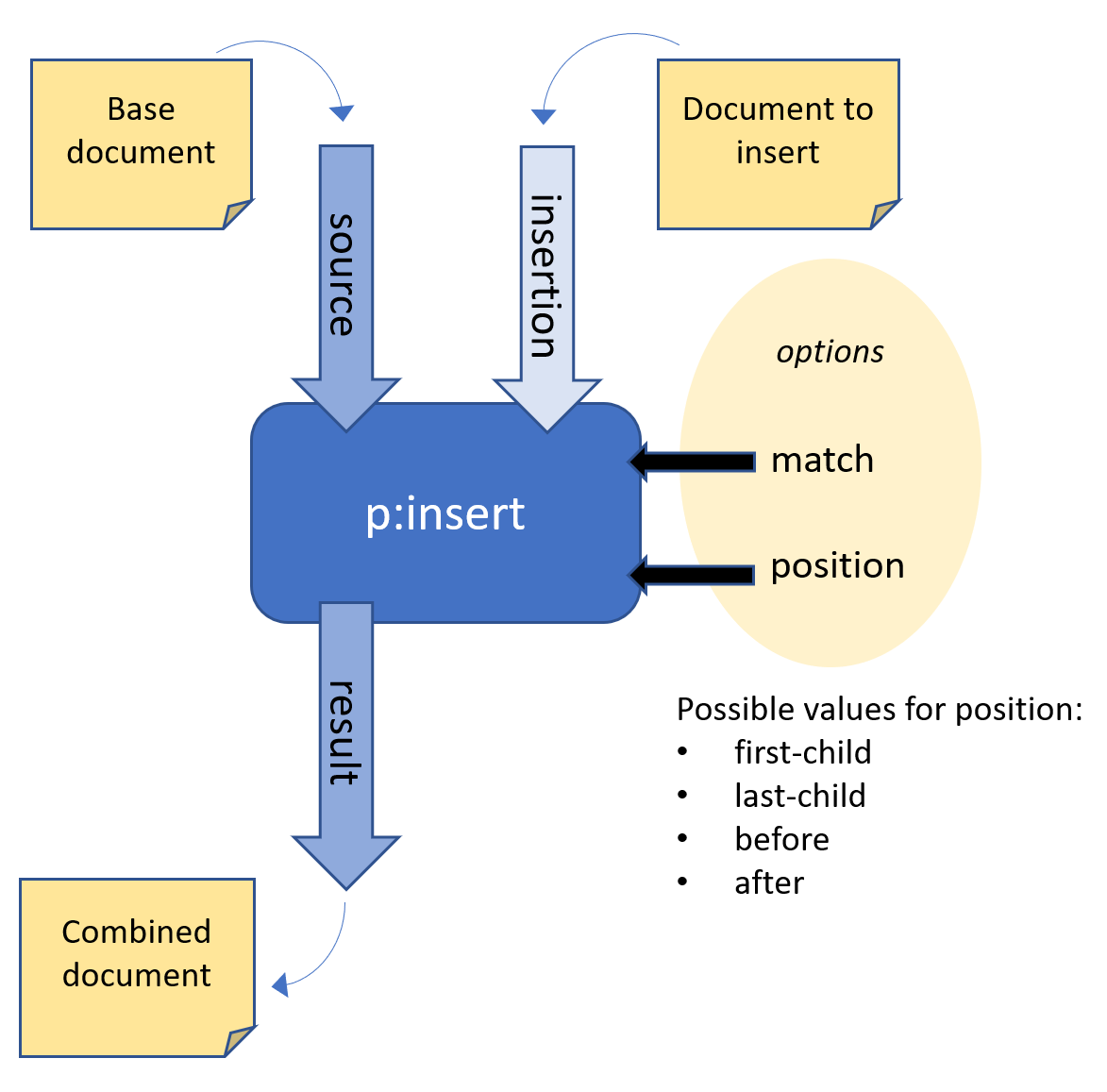
p:insert step
It has three ports:
An input port called
sourcein which the base document, the document we're going to change, flows inAnother input port called
insertion. This receives the document to insert.An output port called
resultthat emits the combined document.
It has two options:
An option called
matchto determine where in the main document the other document must be inserted (e.g./*or/doc//sect1).An option called
positionto determine how this must be done (possible values:first-child,last-child,beforeorafter).
Port Connections
To make pipelines out of steps, you have to be able to connect or bind the ports of the individual steps. Documents must flow into input ports, whether they come from output ports of other steps, from disk, the web or whatever. There are two principal ways to bind or connect ports:
- Implicit binding
An important feature of ports is that one input and one output port of a step can be designated as primary port (by convention called
sourceandresult). Primary ports of steps "auto-connect" when you place steps next to each other in XProc code. In XProc lingo this is called implicit binding.Not only does implicit binding connects steps together, it also connects the primary input and output port of a pipeline to its constituent steps. Here's an example pipeline that chains two XSLT transformations:
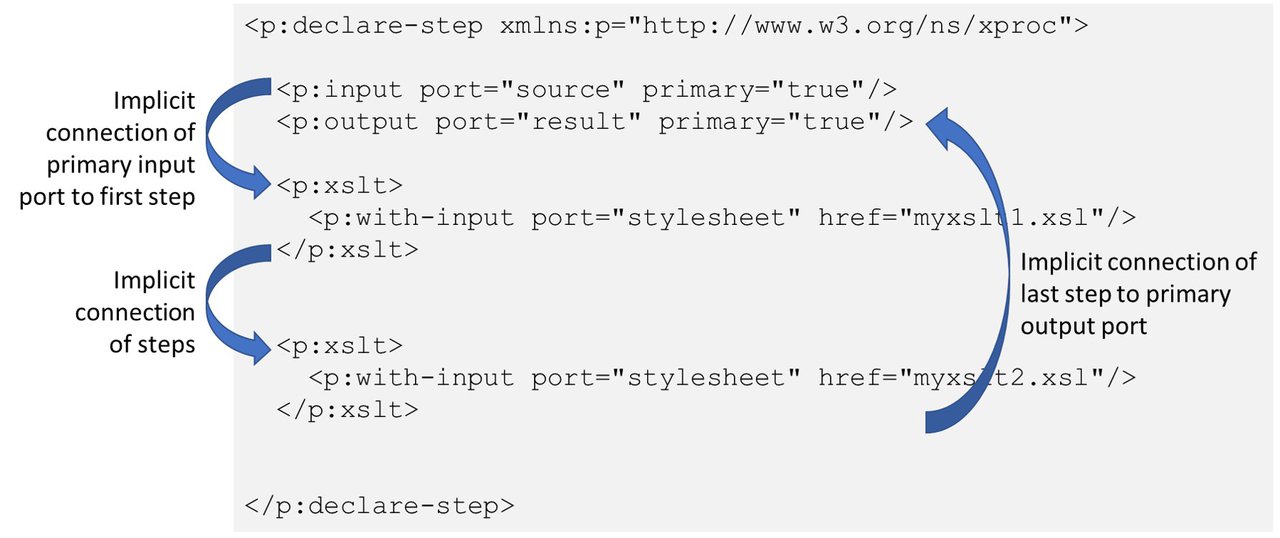
Implicit connections in a pipeline Implicit binding makes pipelines much easier to write and, maybe even more important, to read and understand.
- Explicit binding
Besides implicit binding there is, you might have guessed, explicit binding. With this you explicitly connect an input port (connections are always made from input ports) to some source. This can be:
An output port of some other step in your pipeline.
Something external, usually a file on disk or something from the web.
For example, in Figure 5, “Implicit connections in a pipeline” the
stylesheetports of thep:xsltsteps are explicitly bound to files on disk.An inline document in the XProc code. In defining this document you can use Attribute and Text Value Templates (expressions between curly braces,
{…}) that will expand when evaluated. This is akin to value templating in XSLT and XQuery.Nothing, zilch, empty. This can be useful in some cases.
Programming in XProc
XProc is more than just chaining steps, however useful this in itself already is. It has features that turn it into a full-fledged programming language.
- Looping, branching and error handling
XProc's core steps provide looping (
p:for-each), branching (p:chooseorp:if) and error handling (p:try) functionality.- XPath
Underlying XProc is the XPath programming language (version 3.1) that you probably already know as cornerstone of languages like XSLT and XQuery. All expressions in XProc are XPath expressions. Data types like maps and arrays are fully supported.
- Variables
You can use variables in computing things, provide logical names, etc. When setting the value of a variable it is possible to peek into the document that flows through. For instance to grab the value of the
statusattribute of the root element:<p:variable name="status" select="/*/@status"/>
Like XSLT and XQuery, XProc is a functional programming language and therefore variables are immutable.
Additional information
The XProc 3.0 standard, its accompanying documentation and processors were in November 2019, when this article was written, still under development. We hope to finish the standard end of 2019. Documentation and processors should arrive somewhere in the beginning of 2020.
The XProc standard itself (both the core language specification and the step library) can be found at http://spec.xproc.org/.
There are two XProc processors in the making:
XML Calabash (http://xmlcalabash.com) is the open source XProc processor, developed and maintained by Norman Walsh.
MorganaXProc (http://www.xml-project.com) is the open source XProc processor, developed and maintained by
xml-project/. The 3.0 version is officially branded "MorganaXProc-III".
Both processors also have versions that implement XProc 1.0.
The author of this article is writing a programmer's reference for XProc 3.0. It will be published by XML Press (http://xmlpress.net/) beginning 2020. I'm looking forward to your purchase ;)
XProc is developed on GitHub: http://github.com/xproc. By all means: join us! Discuss and submit issues, fork a repository and make pull requests, stay in touch, we truly appreciate it.
Join the XProc mailing list at https://lists.w3.org/Archives/Public/xproc-dev/.