What is XSLT?
January 1, 2017
Table of Contents
- 1. The task at hand
- 2. How XSLT is different from other programming languages
- 3. The shared data model of XSLT and XQuery
- 4. The shared processing model of XSLT and XQuery
- 5. The leveraging of XSLT stylesheets: polymorphism
- 6. Using both XQuery and XSLT in a single data flow
- 7. XSLT in the browser
- 8. XSLT creating XSLT
- 9. Two very simple coding examples
- 10. Conclusion
The Extensible Stylesheet Language Transformations (XSLT) is one of the most important of the XML technologies to consider in solving your information processing issues. It is also a very different programming language from others, and so understanding what it does and how it works is important when selecting it as part of your solution.
Consider that your XML content is already marked up, identifying portions of content using a set of labels according to some kind of semantics. Perhaps those are display semantics of appearance, but more likely the semantics regard some kind of inherent properties of the information. In aerospace, in automotive, in pharmaceutical, in office documents, in business documents, in proprietary vendor tools and yet many other situations all of the markup languages necessarily differ. The labels marked up in the content are such that the meaning of the content can be interpreted according to how the labels are documented to be used. To assist with this, namespaces can help tremendously in differentiating these labels from those used in other XML vocabularies.
1. The task at hand
XML document translation is required when the labels that you need are different than the labels that you have. When displaying your content in a web browser, HTML has its own set of labels interpreted by the browser with semantics to present the information. When displaying your content on paper, the Extensible Stylesheet Language Formatting Objects (XSL-FO) has its own set of labels interpreted by a composition engine as having semantics to produce print images. When an application publishes an XML vocabulary for consumption, say an ERP system accepting invoice data, and you have your content using the OASIS Universal Business Language (UBL) vocabulary for documents, your information needs to have its labels changed for the information to be used by the ERP system.
As well, you may be transforming your XML information to the same target vocabulary in more ways than one because you have different audiences that perceive your information differently. The authored/generated order and labels may be suitable for editors/reviewers but not suitable for users. Different transformations are needed for the different audiences, and those differences may be subtle or may be extensive.
At its essence, you are creating new separate XML, HTML or text documents from what is found inside your XML documents. That is, you need to express how to create a new labeled tree of your information from your existing labeled tree of your information.
Most programming languages have XML libraries or an API of some kind. You may be tempted to continue using your own favourite language and library to express the transformation. Such languages using the Document Object Model (DOM) offer the logic to change the parts of your document in place and then serialize the tree as output. Alternatively one can use the library to access the information and simply write out the document using program logic, though that really isn't very simple. Taking the responsibility to create the output XML syntax and proper Unicode encodings can be a burden on programmers, not even considering the risk that such is done improperly.
XSLT is a Turing-complete programming language written for and using XML syntax. It takes in well-formed XML syntax and it produces well-formed XML syntax without the programmer having to worry about the variations possible for either. XSLT is defined as an XML vocabulary in its own namespace, and as such, it is fully composable by itself. That is, that an XSLT stylesheet can create an XSLT stylesheet. More on this later.
As its name implies, XSLT is extensible in a standard fashion to access non-standard functionality. Vendors can offer non-standardized functionality such as for data projection, for unique collation algorithms and for custom functions, but in a way that a conforming XSLT processor can gracefully handle unrecognized functionality in a standardized fashion.
2. How XSLT is different from other programming languages
XSLT and its sister specification XQuery (An XML Query Language) are very similar in almost all aspects, except for the very different expression languages written by the programmer. The same data model is used by both. Many vendors offer a single transformation engine that runs both kinds of transformation expression. The same output serialization specification is used by both languages. But whereas XSLT is written in XML, XQuery is not. XQuery is written using a pseudo XML-like syntax that would never parse as an XML document.
Moreover, the primary mindset and writing styles when comparing XSLT expressions (stylesheets) and XQuery expressions are very different. Such differences are critical to writing quality XSLT stylesheets and may impact your team's performance based on their experience in programming approaches.
Most programming languages are written primarily in an imperative style. The logic starts at the top of the program code and works its way down to the end of the code, producing output along the way. There are function calls that jump out to other modules, and inclusion directives that pull in other bits of code into the main block of code, but one typically starts and the beginning and goes to the end. JavaScript, C and Python are but a few examples of imperative programming languages. XQuery is also such an imperative language. The XQuery expression itself is structured along the lines of the output document organization.
Not so with XSLT, which is, at its heart, a declarative programming language. The features and power XSLT brings to the table for transformation are best utilized in the declarative style. It is possible one could declare a single XSLT handler (called a "template") for all content to be triggered by a single event, and write that one handler in the imperative style, and imperative programmers would no doubt find that the easiest way to use XSLT. But that isn't the best way to use XSLT. Programmers need to be skilled in conceiving and establishing granular declarative handling while at the same time finessing event generation to be handled in such a way as to produce the output.
Granted, using callbacks in imperative languages is an example of a declarative programming style. And even XML programming interfaces such as SAX are often set up in imperative languages with callbacks that get control on events triggered by XML syntax. But in most programming languages this is a contrivance built on top of the imperative model.
It is this fundamental difference in the approach to writing stylesheets that separates a good XSLT programmer from a programmer that hacks his way to getting the correct result while using XSLT. While getting the correct result is the end game, writing XSLT well creates a solution that can be leveraged into other solutions and can be maintained with more assurance of reducing the introduction of faults into working code. Writing XSLT well takes practice and requires the skilled programmer to engage a mindset quite different from that required when writing in traditional imperative languages. These points are illustrated later.
Consider the case study http://www.cranesoftwrights.com/links/ipepaper.htm of the rendering of US Intelligence Documents written in XML. After decades of different intelligence organizations producing drastically differently-appearing intelligence reports, the US intelligence community has agreed upon a single XML vocabulary used by agents to record information. In the project, the organizations wanted to continue seeing the information in their own individual style where only low-level constructs such as sections, paragraphs, tables, graphics, etc. look the same. The overall renderings, such as title pages, tables of content and layout constraints are very different. The declarative style in XSLT is ideal for creating a single solution with overriding components. Declared components that are not overridden render the portions of content the same across all documents. Declared components that are overridden for each organization render the portions of content that are different. Designing from the bottom up in the declarative style created a solution easily leveraged as required across multiple installations.
Seasoned developers using traditional programming languages must also appreciate that the data and processing models underlying XSLT are different from what they have been dealing with. No doubt programmers are well used to considering the syntax of the files that are input to a program, the syntax of the files that are output from a program, and the steps in their program to create output syntax from input syntax. Relying on such a traditional approach can hinder a programmer's perspective of XSLT and prevent one from properly understanding that the writing and processing of an XSLT stylesheet is entirely divorced from the syntax of the input and output files. As shown later, the programmer is given the information that was found in the input document , and can specify how to arrange the information to be placed in the output document, but the programmer has no interaction with the syntax of either input or output documents.
3. The shared data model of XSLT and XQuery
One can choose from a number of syntax variations when marking up XML files. As an exercise, try to think of the five different syntactic ways to mark up the simple math expression "a<b"[1]. Thankfully, the XML processor found in the XSLT and XQuery processor accommodates all the vagaries of XML syntax and distills the tree of labeled Unicode-character information found in your document. Branches and leaves in this tree are called nodes and each node has a value and a relationship to other nodes above, beside and below the node. The nodes also have names, those being the labels used in the XML (such as input elements), so that one can identify in the transformation the parts of your document when creating the newly-labeled information (such as output elements).
This labeled tree of your XML document has a formal model defined as part of the XQuery and XPath (the XML Path Language) specifications, and it is called, quite obviously, the XDM (the XQuery and XPath Data Model). There are only seven kinds of node needed to express in a tree of nodes every possible XML document. Where order is defined in XML, such as the order of an element's children, order is preserved in the tree of nodes created by a vendor's implementation. Where order is not defined in XML, such as the order of an element's attributes, the order implemented by a vendor is arbitrary and must be handled appropriately in a well-written stylesheet. With such in mind, then, a well-written stylesheet can access the input data found in an XML file in an identical fashion regardless of which vendor's tool is being used.
But the input data need not be XML syntax in order to create an XDM suitable for access by XQuery and XSLT. Through the facility of data projection, a vendor can offer to present to the transformation any content at all, provided that content is presented as a complete XDM tree of nodes of the seven different types. At a minimum, every vendor must offer to project an XML file as an XDM tree of nodes, and to project a simple text file input that is not in XML syntax as an XDM tree comprising a single text node. Beyond that, vendors can get very imaginative in what they offer. Quite obviously database vendors project their database tables of content as an XDM tree to both XQuery and XSLT processes used to create output results. Relational tables can be projected as nodes of rows and columns of content.
This diagram depicts a number of possible data flows using a single transform for two different inputs or two different transforms for a single input.

In all cases the illustrated input to the transform is a dotted triangle tree of source XDM nodes, and the output from the transform is a dotted triangle tree of result XDM nodes. At the top an XML document is interpreted as the tree of source XDM nodes. The other tree of source XDM nodes shown part way down the diagram is created through source data projection of some non-XML content. While the diagram shows only XML documents being serialized from the tree of result XDM nodes, in fact XSLT and XQuery share the use of a serialization specification that provides for creating either XML, HTML, XHTML or simple text syntax entities from the tree of nodes. The diagram also shows only a single input and single output to the transformation process whereas, in fact, a single transformation can access multiple trees of source XDM nodes and create multiple trees of result XDM nodes, possibly serializing each result tree using a different syntax.
It is important to note that vendors compete on both the performance of standard features, and the facilities available in extended features beyond the specifications. You need to be aware of locking yourself to a vendor's product should you choose to exploit the extended features. At a minimum, because there are no standardized requests for data projection other than XML and text, you need to distinguish how to request non-XML and non-text content be offered using XDM. Beyond that, however, you can choose to stick to the available standardized behaviours or step beyond product independence by invoking vendor-specific behaviours.
Your programmers who have for years been focused on data files and their syntax need to look at XSLT and XQuery differently, because your XML documents are not regarded as XML syntax, they are regarded as XDM nodes.
4. The shared processing model of XSLT and XQuery
The shared XDM data model of looking at input and output information to and from the transformation process infers that the processing models be similar and this is, in fact, the case. A number of vendors offer an underlying engine implementing a processing model that effects the transformation on nodes, regardless of the expression language used to express the transformation. Thus the product equally supports either XSLT stylesheets or XQuery expressions, as either one of these is interpreted as yet another tree, that being a tree of operation XDM nodes.
This diagram depicts the nature of the transformation process, creating a result XDM nodes as a mixture of source XDM nodes and transform operation XDM nodes. It also shows both the data projection available to create the source XDM nodes and the many possible serialized results and interpretations of the result XDM nodes.
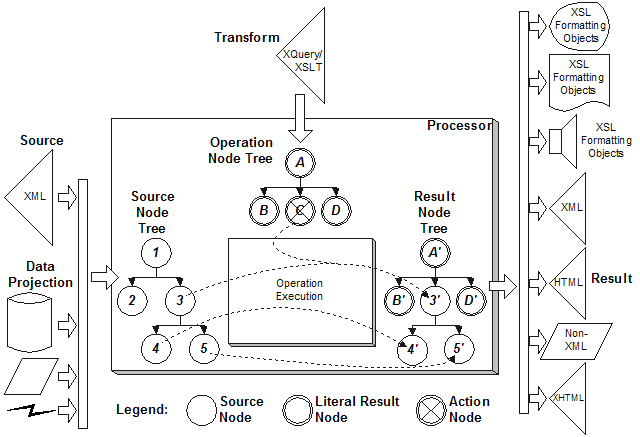
Note the convention in the diagram of using the prime symbol to associate in the output tree from which input tree a given node is copied.
The diagram illustrates how the processing model establishes the independence of the transformation logic from the syntax of the input and output files. The transformation acts solely on operation nodes and source nodes to produce result nodes. The processor worries about the syntax, not the programmer.
Again, this is very different from what your programmers are used to dealing with. XSLT and XQuery are assembling the result based on the operations performed on the input under the programmer's control. The programmer is not writing out syntax. The programmer doesn't have to think of the vagaries of what can be in the XML documents. There is no input buffering or line handling to be done as this is all handled by the processor behind the scenes. Your programmers need to focus on how best to express how the assembly of inputs into the results is best accomplished.
5. The leveraging of XSLT stylesheets: polymorphism
The opportunities to leverage into multiple solutions the investment in a given stylesheet are found in the declarative nature of the stylesheet. This benefit can be overlooked when assessing XSLT compared to traditional imperative programming languages. Choosing to use XSLT is not simply choosing to use the latest and greatest XML-oriented technology, it is choosing a programming environment more flexible and robust than others at creating structured results from structured inputs.
The declarative approach of writing an XSLT stylesheet requires the programmer to view the
transformation very differently than with the top-down imperative approach. The programmer
must establish a particular granularity of fragments of the output that is to be associated
with and matched with the granularity of the input XML. Each of these fragments is then made
to be a template of the result associated with the processing of a single node of the input.
This association need only be made once for each type and name of input node and the template
is copied to the result every time a node of the given type and name is processed. For
example, a template comprising of an HTML output element node named "img" representing the
eventual to-be-serialized output of <img> could be associated with the
processing of an element node named "figure" representing the projected XML DocBook input of
<figure>.
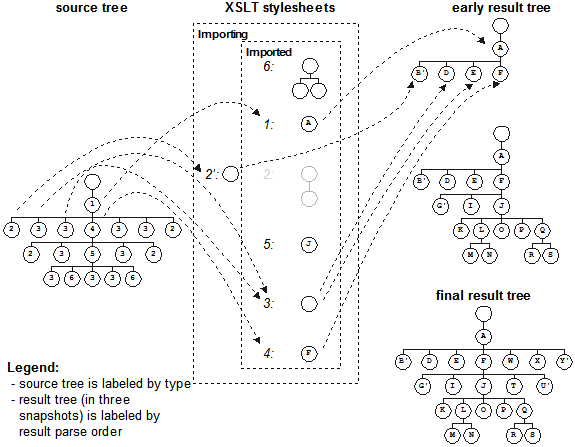
This is depicted in this diagram where the input source nodes are labeled with numbers and the output result nodes are labeled with letters. The stylesheet governing the transformation is a collection of templates associated with each input node by that node's type and name. As each input node is encountered, the stylesheet assembles the result as the next portion of the result.

The programmer is always in control over which source nodes are pushed at the at the collection of templates, and the XSLT engine responds to each pushed node by matching the most appropriate template with which to build the result. Everything is seen as nodes, not as start tags or end tags or empty tags.
Looking at the diagram you can see the template for the node identified as "2" has a
parent/child combination of two nodes. As the result is constructed, the four nodes so
identified are pushed to the stylesheet and trigger the creation of the eight result nodes
"B/C", "G/H", "U/V" and "Y/Z". Perhaps this node "2" is the XML
<figure> element and the two nodes in the template are the
<div> element parent and the <img> element
child. Every <figure> in your input XML document produces the pair
<div><img> in the output HTML document for a browser.
When assessing long-term maintenance costs of your stylesheets, a valuable property of XSLT that distinguishes it from most other programming languages is that it is "side effect free". Global variables do not vary in that they are bound with final values when declared. Templates can only see their own variables and global variables, not the variables of other templates. There is nothing one can do in a template that impacts on the processing of all other templates. This makes for very robust transformations during the maintenance phase of a project, as it is impossible to "break" templates that are not touched when touching other templates. The more granular the templates, that is, the more templates there are, the more isolated are working bits of code.
And the more templates there are, the more opportunities there are to wrap the stylesheet with another stylesheet that overrides the declared handling of your XML document. This offers a kind of polymorphism for associated template definitions. Such an override leverages the overridden stylesheet by providing a different definition of how to build the result. Creating a result for a new audience can exploit the stylesheet for an existing audience, changing only those behaviours that are needed and preserving those behaviours that don't need to change. Perhaps you need to suppress specific information for the new audience that was exposed for the old audience. A common requirement is to augment an end-user's page with editorial details important to reviewers in order to create the review copy that is never seen by an end user. But the reviewers can look around the augmentations to see the content as would be otherwise produced.
Consider in this diagram how the importing stylesheet provides an alternative handling for
the node identified as "2" as the imported stylesheet shown in the earlier diagram. Now when
the result is built, a single node is added to the tree for each of the four input nodes to
create the prime-labeled nodes "B'", "G'", "U'" and "Y'". This illustrates how to suppress
writing out nodes "C", "H", "V" and "Z", or how to replace nodes "B", "G", "U" and "Y"
entirely. Following the earlier example, now every <figure> in your
input XML document becomes a different kind of <div> in your output HTML
without an <img>. Perhaps the output is targeted to a visually-impaired
audience and so the graphical image is suppressed and the text presented differently for an
audio reader. In this example, nothing else is different, only the handling of
<figure>.
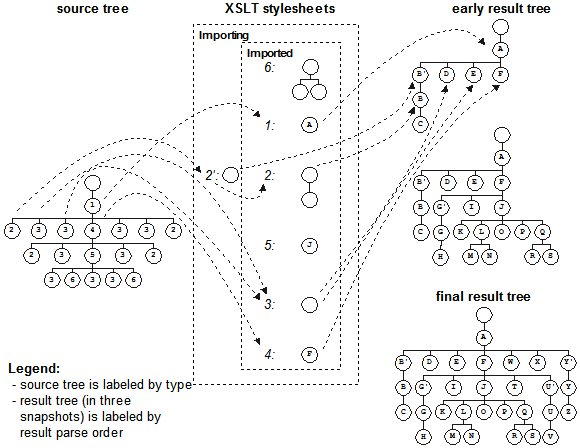
Consider in the next diagram how the importing stylesheet augments the existing handling
for the node identified as "2" as the imported stylesheet shown in the earlier diagram. Now
when the result is built, three nodes are added to the tree for each of the four input nodes,
one being new and the other two being the original output. In this way the result tree is
created with the nodes "B'/B/C", "G'/G/H", "U'/U/V" and "Y'/Y/Z". This illustrates how to
augment the output with additional information while not touching the original stylesheet.
Following again the earlier example, now every <figure> in your input
XML document becomes a wrapping <div> of file name or other image
metadata that surrounds the <div><span> created by the imported
stylesheet. Perhaps this output is targeted to editorial staff who need to see important
information hidden from the main audience but critical to the task of reviewing your XML
document content being published. Again, only the handling of <figure>
is being changed.
By wrapping the stylesheet for the main audience with two different stylesheets for two
other different audiences, the bulk of the work in the main stylesheet does not have to be
maintained separately. The cost of developing the main stylesheet gets leveraged for the new
audiences with little relative effort. Compare this approach with what would be required in
imperative languages and the different assembly and maintenance of imperative fragments. With
XSLT, the imported stylesheet remains whole and the importing stylesheet provides the
polymorphism of different ways to handle the <figure> element in your
XML document for different audiences.
An interesting opportunity is to implement an 11th-hour production fix to a read-only stylesheet that perhaps is locked in to a source code control system. The importing stylesheet supplants the undesirable processing with the required processing until the required processing can be migrated into the base stylesheet.
Using these techniques a project team can create libraries of debugged and working stylesheets that are to be pulled into and leveraged in multiple solutions. Fragments can be overridden or augmented, but the side-effect-free nature of the language guarantees the fragments cannot be "broken" by the influence of other templates. This is the essence of the US intelligence document publishing system cited earlier: the imported stylesheets provide the common base behaviours while the importing stylesheets provide the agency-specific appearances and augmentations, all done in a robust fashion enabling quick new deployments and system-wide maintenance. Moreover, the maintenance experience across multiple XSLT projects has been testament to the ease of adding new functionality without disturbing existing functionality.
6. Using both XQuery and XSLT in a single data flow
While XQuery does not offer the same level of polymorphism of common code fragments, the imperative nature is very attractive to traditional programmers. One might consider, then, using XQuery in the data flow when assembling content and using XSLT in the data flow when publishing content. This would be depicted as follows.
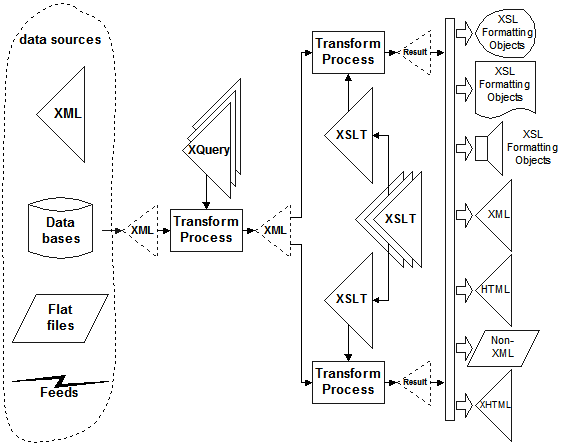
The diagram shows two wrapper XSLT stylesheets importing the same collection of imported stylesheets to produce distinctive results from the one structured input created by the XQuery interpretation of projected data. Of course XSLT could be used in the imperative fashion in place of XQuery and staff is only learning one XML-based language rather than two. The opposite, however, of trying to deploy XQuery for the leveraged common code polymorphism available in XSLT would be a programming and maintenance challenge.
7. XSLT in the browser
Where to deploy XSLT online can be as important as using XSLT in the first place. The basic choices are running the transformation directly in the user agent, or running the transformation on the server, either statically in advance of to the connection from the browser or dynamically in response to browser interaction.
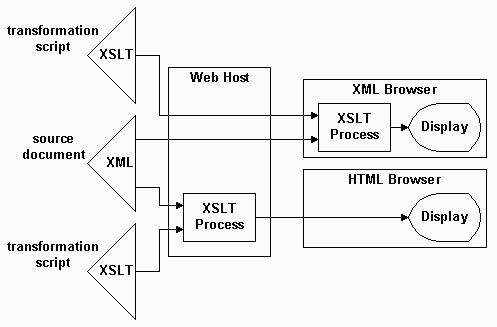
It is important to realize, however, that there are two ways in which XSLT can be run in the browser user agent. Many browsers offer only XSLT 1.0 support natively, and even then, not consistently. Different choices of XML processor and different choices of XSLT processor result in differing and inconsistent results between browser implementations. The very viable alternative offered with the Saxon/CE (Client Edition) http://www.saxonica.com/ce/index.xml XSLT processor is fully-compliant XSLT 2.0 support executing in the browser as compressed JavaScript code without any server-side executables. Provided that JavaScript is not disabled, all modern web browsers execute the engine consistently to produce identical results for all users. Moreover, the XSLT 2 facilities are far superior to the available XSLT 1 facilities.
8. XSLT creating XSLT
A final nuanced consideration is available due to the nature of XSLT being written using well-formed XML syntax. Because XSLT produces well-formed XML syntax, an XSLT transformation can create an output XSLT transformation. One interprets an XML document describing how information is to be processed and outputs the XSLT stylesheet implementing the processing so described. This is depicted as follows.
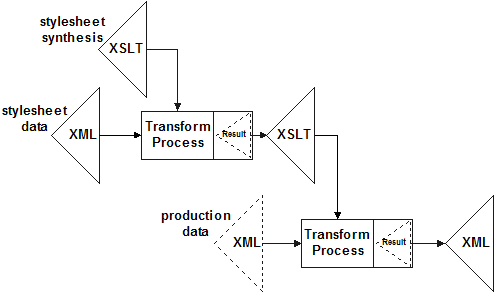
This is not simply academic. The very powerful Schematron (ISO/IEC 19757-3) value validation language is an XML vocabulary where one expresses assertions and rules about XML content. When implemented using XSLT, the freely-available Schematron XSLT stylesheets consume a Schematron expression and emit the equivalent in XSLT logic to be performed on the XML input. The output of executing that generated XSLT logic against the production data is the validation report.
9. Two very simple coding examples
These two simple examples are excerpted from the five hours of free preview of the 24-hour streaming XSLT hands-on training class on Udemy. This is the only code included in this article and the concepts in this working code are greatly simplified to illustrate the contrast between the imperative and declarative programming styles when writing XSLT. I've limited the examples to XSLT 1.0 so that these can be run in a browser if desired.
First, consider a test XML document of a summary of sales of products to customers.
01 <?xml version="1.0"?> 02 <!DOCTYPE sales [ 03 <!ELEMENT sales ( products, record )> <!--sales information--> 04 <!ELEMENT products ( product+ )> <!--product record--> 05 <!ELEMENT product ( #PCDATA )> <!--product information--> 06 <!ATTLIST product id ID #REQUIRED> 07 <!ELEMENT record ( cust+ )> <!--sales record--> 08 <!ELEMENT cust ( prodsale+ )> <!--customer sales record--> 09 <!ATTLIST cust num CDATA #REQUIRED> <!--customer number--> 10 <!ELEMENT prodsale ( #PCDATA )> <!--product sale record--> 11 <!ATTLIST prodsale idref IDREF #REQUIRED> 12 ]> 13 <sales> 14 <products><product id="p1">Packing Boxes</product> 15 <product id="p2">Packing Tape</product></products> 16 <record><cust num="C1001"> 17 <prodsale idref="p1">100</prodsale> 18 <prodsale idref="p2">200</prodsale></cust> 19 <cust num="C1002"> 20 <prodsale idref="p2">50</prodsale></cust> 21 <cust num="C1003"> 22 <prodsale idref="p1">75</prodsale> 23 <prodsale idref="p2">15</prodsale></cust></record> 24 </sales> |
| Sample product sales source information |
This XML document is structured not around any particular presentation. Rather, the XML is
structured around the inherent relationships of the information expressed in a tree. Lines
14-15 carry all product information. Lines 16-23 carry the record of all product sales to
customers, organized by customer. In order not to repeat the titles of products in the sales
records, the products are referenced internally using the XML IDREF semantic of referencing an
attribute of type ID. The embedded DTD in lines 2 through 12 include the declaration on line 5
ascribing ID-ness to the id= attribute of the
<product> element.
Now let's consider two HTML presentations of that information as two separate transformations shown in two browser windows where on the left is a tabular presentation of the information, and on the right is a list presentation of the same content.
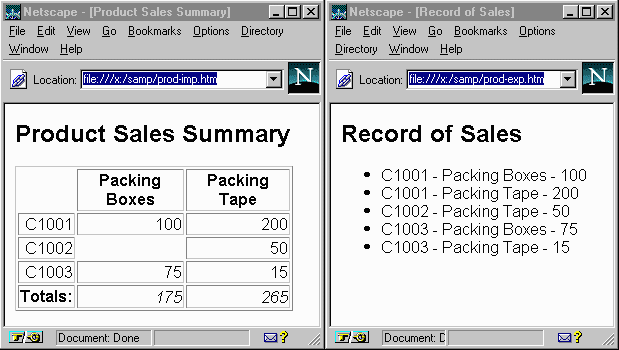
We need to write the stylesheet that builds from the XML input to an HTML output with elements and attributes expressing HTML semantics of presentation, because browsers do not recognize the sales-oriented elements used in the input. The information doesn't change in this example, only the arrangement of the information and the elements used in that new order. And we need two transformations taking the same XML input so that we get two different HTML outputs.
Consider first using XSLT in an imperative manner, much like one would write XQuery, where the entire self-contained expression is a single template.
01 <?xml version="1.0"?> 02 <!--XSLT 1.0 - http://www.CraneSoftwrights.com/training --> 03 <html xmlns:xsl="http://www.w3.org/1999/XSL/Transform" 04 xsl:version="1.0"> 05 <head><title>Product Sales Summary</title></head> 06 <body><h2>Product Sales Summary</h2> 07 <table summary="Product Sales Summary" border="1"> 08 <!--list products--> 09 <tr align="center"><th/> 10 <xsl:for-each select="//product"> 11 <th><b><xsl:value-of select="."/></b></th> 12 </xsl:for-each></tr> 13 <!--list customers--> 14 <xsl:for-each select="/sales/record/cust"> 15 <xsl:variable name="customer" select="."/> 16 <tr align="right"><td><xsl:value-of select="@num"/></td> 17 <xsl:for-each select="//product"> <!--each product--> 18 <td><xsl:value-of select="$customer/prodsale 19 [@idref=current()/@id]"/> 20 </td></xsl:for-each> 21 </tr></xsl:for-each> 22 <!--summarize--> 23 <tr align="right"><td><b>Totals:</b></td> 24 <xsl:for-each select="//product"> 25 <xsl:variable name="pid" select="@id"/> 26 <td><i><xsl:value-of 27 select="sum(//prodsale[@idref=$pid])"/></i> 28 </td></xsl:for-each></tr> 29 </table> 30 </body></html> |
| Imperative approach to writing XSLT |
It is critical to understand that in XSLT we are manifesting the output from within the
stylesheet expression, not using function calls to synthesize elements and attributes out of
thin air (though this is available and sometimes it is the most expedient way of dynamically
calculating the output information). Lines 3 and 30 express, respectively, the start tag and
the end tag of the apex <html> element for the output. Just its presence
in the stylesheet is enough to create the output. In fact, this is the nub of XSLT: the
stylesheet manifests the output in the form of a template that is triggered by and fleshed out
with the input information. In the imperative example, the entire stylesheet is the template
of the result tree.
Within every template, large or small, the elements not in the XSLT namespace are used directly in the result, while the elements in the XSLT namespace are instructions that are interpreted as control constructs or action directives obtaining or assembling information to be included under and beside the manifest result elements.
The elements seen in lines 5 through 7 are simply copied to the result, as there are no
instructions encountered, beginning the table with the <table> element
and starting the table header with the <tr> element and placing an empty
<th> element as its first child. This empty table header is the blank
cell at the start of the heading line. Line 10 begins the <xsl:for-each>
instruction, ending on line 12, under which one finds a template of the manifest expression of
a single <th> table header element. The instruction is addressing all of
the <product> elements of the document using the address
"//product", and so the template is repeatedly added to the result once
for each <product> while having the focus of embedded instructions at
each <product> element in turn. The <xsl:value-of>
instruction on line 11 addresses the current focus when using the ".", and
so the stylesheet is adding to the result a text node whose value is the text value of the
<product> element. Thus, the second and subsequent cells of the
heading line contain all of the product names.
The <xsl:for-each> element and its descendants on lines 14 through
21 visit each <cust> element and build a row of the customer number
information and each of the corresponding sales number items. Line 15 shows the binding of the
current node to a variable named "customer". Lines 18 and 19 have an XPath address finding the
appropriate information to be included in the report.
Finally lines 23 through 28 build the totals row, including a cell for the word "Totals" and using on line 27 a built-in function to sum all of the cells addressed by the stylesheet. The programmer doesn't have to implement the summation logic, it is enough to simply ask the processor to sum the values of the addressed nodes.
Consider next the use of the declarative style to walk through the XML in order to create
an HTML unordered list of list items. Note how there are three template rules, one for the
root node (addressed as "/" in XPath), one for the element
<record> and one for the element
<prodsale>.
01 <?xml version="1.0"?> 02 <!--XSLT 1.0 - http://www.CraneSoftwrights.com/training --> 03 <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" 04 version="1.0"> 05 06 <xsl:template match="/"> <!--root rule--> 07 <html><head><title>Record of Sales</title></head> 08 <body><h2>Record of Sales</h2> 09 <xsl:apply-templates select="/sales/record"/> 10 </body></html></xsl:template> 11 12 <xsl:template match="record"> <!--processing for each record--> 13 <ul><xsl:apply-templates/></ul></xsl:template> 14 15 <xsl:template match="prodsale"> <!--processing for each sale--> 16 <li><xsl:value-of select="../@num"/> <!--use parent's attr--> 17 <xsl:text> - </xsl:text> 18 <xsl:value-of select="id(@idref)"/> <!--go indirect--> 19 <xsl:text> - </xsl:text> 20 <xsl:value-of select="."/></li></xsl:template> 21 22 </xsl:stylesheet> |
| Declarative approach to writing XSLT |
Processing begins by building the result tree using the template of the template rule for
the root node declared in lines 6 through 10. Lines 7 and 10 have the start and end tag for
the <html> element and its descendants. Line 9 is the instruction
<xsl:apply-templates/> that addresses <record>
elements and instructs the processor to push those elements to the stylesheet.
There is a template rule for <record> elements to handle the events
generated by having pushed them, and line 13 adds the <ul> unordered
list element to the result, under which, the <xsl:apply-templates/>
processes (pushes) the children of the current node <record>.
There is no template rule for the child "<cust>" elements, and so
the built-in processing simply pushes the child nodes at the stylesheet for further
processing. The children of the <cust> elements are
<prodsale> elements.
There is a template rule for <prodsale> elements and lines 16
through 20 construct the list item that is added to the result tree.
In this way the result tree is built in a piecemeal fashion starting with the
<html> element and going down to all of the leaf
<li> elements to express a complete HTML document for rendering in the
browser window.
Contrast the two solutions by the isolation of the templates. There is but one template in the imperative solution and so that stylesheet can be used to create only one result. There are three templates in the declarative solution and so that stylesheet can be leveraged to produce multiple results by having the templates overridden by multiple importing stylesheets. And any logic in any of the three templates has no influence on any of the other templates, so maintaining a template will not break others.
XSLT and XQuery are Turing-complete programming languages created using and created for XML, in contrast to languages treating XML as an adjunct to their base nature.
The expression language of XSLT offers a number of benefits over XQuery and other imperative languages, primarily in the polymorphism of transformation behaviours for creating differing but related solutions.
While the language requires training and practice in the art of creating nuanced and powerful stylesheet fragments, the investment is returned in the integrity, flexibility and robustness of the stylesheets deployed.
Choosing to use XSLT is important to your information processing planning for XML and other structured content such as is found in databases. It is worth the effort to deploy properly.
[1] The five ways to mark up the less-than character in the string
"a<b" are:
"
a<b""
a<b""
a<b""
a<b""
a<![CDATA[<]]>b"