A Theory of Compatible Versions
December 20, 2006
Making versioning work in practice is a difficult problem in computing. Arguably, the Web was able to increase dramatically in popularity because evolution and versioning were built into HTML and HTTP. Both systems provide explicit extensibility points and rules for understanding extensions that enable their decentralized extension and versioning. This article describes a set-based model for explicit extensibility and understanding extensions that maximize the versioning capabilities of any language, including languages defined by XML Schema or other XML vocabulary formalisms. Using some simple set theory, we will show that providing extensibility in the first version of a language is the key to compatible evolution.
We will start with an example to illustrate. There is a Name language that specifies that a name contains a first and last, in order. The first and last must contain alpha characters only. We call instances or occurrences of the languages "Texts." Any Texts that are valid according to the Name Language are in the Defined Text Set.
We can model the Defined Text Set graphically as:

Figure 1.
In our example, we'll do the necessary thing and plan for extensibility. The name can be extended, so the Name Language defines that it will accept anything after the last. This content model is first, last, *. For example, first, last, and middle are accepted. All Texts in the Defined Text Set and more are accepted with this extensibility. The set of texts that are accepted in the language is called the Accept Text Set. By necessity, the Accept Text Set is larger (>) than the Defined Text Set--in set theory, a superset. Graphically, this is:
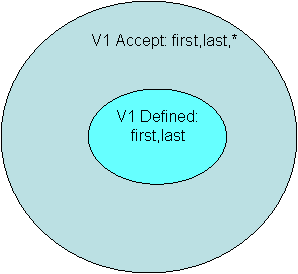
Figure 2.
There is a critical distinction between the items that are in the Defined Text Set (names with only first and last) and the items that are in the Accept Text Set. There are many items that are not in the Defined Text Set and are in the Accept Text Set.
We call the gap between the Defined Text Set and Accept Text Sets the extensibility gap. The extensibility gap is crucial for versioning because the gap is the place that future versions of the language will fill with subsequent definitions. The gap between the Accept Text Set and the Defined Text Set, achieved via extensibility, is the key to allowing forward and backward compatibility. This is because the Accept Text Set of Version 1 allows texts that are not in Version 1 Defined Text Set but may be in Version > 1 Defined Text Set.
To achieve compatibility, the extensibility point must be coupled with a processing model that converts (or maps or substitutes or transforms, etc.) a Text in the Accept Text Set into a Text that is in the Defined Text Set. We call this process a substitution rule.
One substitution rule is the "Must Ignore Unknowns" rule. It specifies that anything unknown but allowed is ignored. By ignoring the extension, the text is in the V1 Defined Text Set. It is the unknown extension that has made the text into something that is not in the Defined Text Set, so ignoring it moves the text into the Defined Text Set. The substitution looks something like:
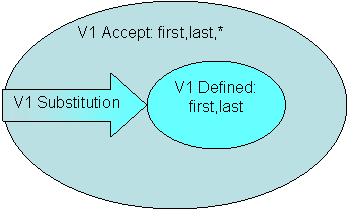
Figure 3.
If the processing model for extensions were something like "catch fire and die if unknown" (obviously not a substitution rule), then there is no possible way of introducing an extension without also revising the Defined Text Set, and thus no forward compatibility.
There is also some subtlety in the exact nature of the extensibility point. It could allow anything at all, such as: first, last, first or even first, last, last. Or it could allow only things that aren't already defined, so first, last, first would be disallowed. We differentiate these types by calling them "inclusive" and "exclusive" extensibility, but we will put this distinction aside.
Next Version
The Name Language Version 2 contains a new term, an optional middle, which must contain alpha characters only. In the texts of the language, middle goes after last: name = first, last, ?middle, *.
The V2 Defined Text Set, V2 Accept Text Set, and Substitution between them looks like:
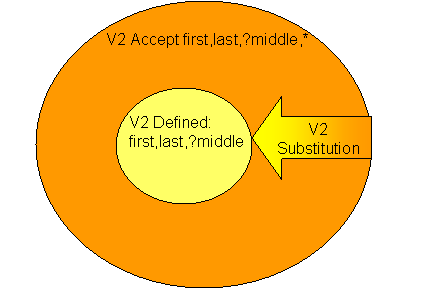
Figure 4.
There are four sets defined: V1 Defined Text Set, V2 Defined Text Set, V1 Accept Text Set, and V2 Accept Text Set. We added an item to the Defined Text Set so the change in the Defined Text Set from V1 to V2 is an expansion. As a result, the V2 Defined Text Set is greater than (a superset of) the V1 Defined Text Set. The V2 Accept Text Set is a subset of the V1 Accept Text Set. This is because some of the middle names that are in V1 Accept Text are not in V2 Accept Text Set. We can show the expansion of the Defined Text Sets and the contraction of the Accept Text Sets by combining the V1 and V2 diagrams together:
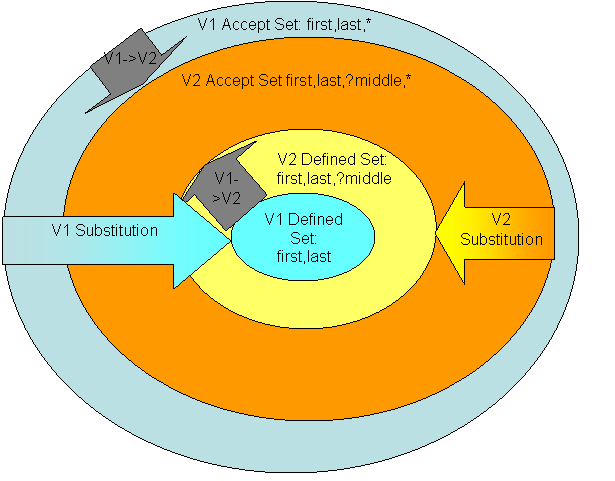
Figure 5.
Compatibility
Any document that is in the V1 Defined Text Set is in the V2 Defined Set, so V2 is backward compatible with V1.
We had to pull a slight trick to achieve backward compatibility: we specified that it was one of the items in the V1 Defined Text Set. If there was an extension to a language--say, a "suffix" was added--then that language is no longer V1. It is V.Not1. Our compatibility guarantees are only for V1 and V2, not for V.Not1.
More formally:
V2 is backward compatible with V1 if V2 Defined Text Set > (superset) V1 Defined Text Set.
Any Text in the V2 Defined Text Set is in the V1 Accept Text Set, so V1 is forward compatible with V2. Formally:
V1 is forward compatible with V2 if V1 Accept Text Set > (superset) V2 Defined Text Set.
Combined together:
V2 is compatible with V1 if V1 Accept Text Set > V2 Defined Text Set > V1 Defined Text Set.
We have shown that forward and backward compatibility is only achievable through extensibility, and the process of compatible versioning is gradually narrowing the extensibility gap between the Defined Text Set and the Accept Text Set.
Incompatibility
We can show an incompatible extension. Imagine that the V2 Defined Text Set and Accept Text Set specify that the middle name must occur between the first and last, rather than at the end. That means some of the members of V2 Defined Text Set are not in V1 Defined Text Set or V1 Accept Text Set. We can show this as V2 not being completely inside V1:
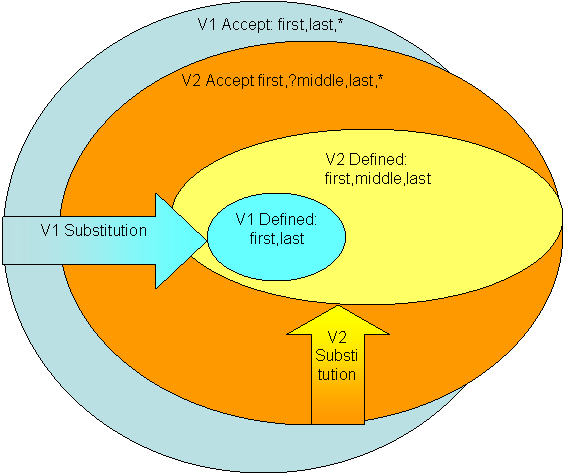
Figure 6.
Partial Understanding Extends Compatibility
The previous examples showed a V1 Name language processor that used the entire name text set and required the correct ordering per the Accept and Defined Text Sets. There are many scenarios where a processor will only consume part of the Defined Text Set. We can imagine an application that only looks at first names and ignores everything else. My favorite example of this is a "Baby Name" Wizard. It might use a simple XPath expression to extract the first name from inside the name. Its Accept Text Set is *, first,*.
Partial understanding affects both the Defined Text Set and Accept Text Set. Partial understanding increases, or supersets, the Accept Text Set because the process of extracting the subset needed means that extra content, legal and illegal under V1 Accept Text Set, is ignored. Partial understanding decreases, or subsets, the V1 Defined Text Set because only part of the Defined Text Set is understood.
We can call the V1 Accept Text Set superset that is used the "V1' Accept Text Set" and the V1 Defined Text Set subset that is used the "V1' Defined Text Set." In this scenario, the sets look like:
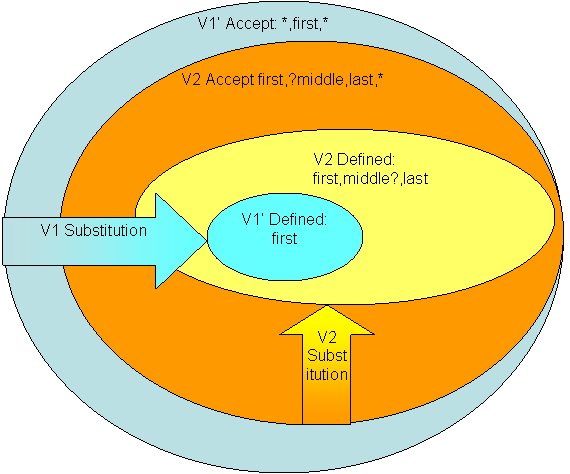
Figure 7.
Partial Understanding and Compatibility
The compatibility guarantee that accounts for partial understanding and the subset of V1(V1') that is used is:
V2 is compatible with V1' if V1' Accept Text Set > V2 Defined Text Set > V1' Defined Text Set.
V1 is compatible with V1' if V1' Accept Text Set > V1 Defined Text Set > V1' Defined Text Set.
In this particular case, we see that V1 and V2 are compatible with V1' because the V1' Accept Set is a superset of V1 and V2. V1 is incompatible with V2 because V2 Defined Text Set is not compatible with V1 Accept Text Set. Because the V1' Accept Text Set is more relaxed than the V2 Accept Text Set, the addition of the middle name between the first and last is actually a compatible change using partial understanding!
The use of partial understanding has changed an incompatible change into a compatible change. Extrapolating from this, the more that partial understanding is used, the more changes will be compatible rather than incompatible.
A language designer will usually not know which processors consume which subsets of the Defined Text Set. Effectively, it will not know whether consumers are V1-, V1'-, or V2-compliant. Generally, a processor should produce a text that is valid to the V1 Defined Text, rather than the V1' Defined Text Set.
The previous three examples show a mixture of compatible and incompatible evolution. In one instance, the addition of a new term is an incompatible change. In two others, it is a compatible change because the addition is in the expected extension area, or because of partial understanding.
Conclusion
Languages can be compatibly versioned successfully if the first version of a language defines an Accept Text Set that is a superset of the Defined Text Set, as well as a substitution rule for transforming texts in the Accept Text Set into the Defined Text Set. After that, a compatible change can be made if a second version of the language must have a Defined Text Set larger than the first version and an Accept Text Set smaller than the first. Partial understanding increases compatibility by the creation of an Accept Text Set that is a superset of the first version that accepts a subsequent Text.