Getting started with XSLT and XPath
August 23, 2000
Examining working stylesheets can help us understand how we use XSLT and XPath to perform transformations. This article first dissects some example stylesheets before introducing basic terminology and design principles.
2.1 Stylesheet examples
Let's first look at some example stylesheets using two implementations of XSLT 1.0 and XPath 1.0: the XT processor from James Clark, and the third web release of Internet Explorer 5's MSXML Technology Preview.
These two processors were chosen merely as examples of, respectively, standalone and browser-based XSLT/XPath implementations, without prejudice to other conforming implementations. The code samples only use syntax conforming to XSLT 1.0 and XPath 1.0 recommendations and will work with any conformant XSLT processor.
| Note: | The current (4/14/2000) Internet Explorer 5 production release
supports only an archaic experimental dialect of XSLT based on an early working draft
of
the recommendation. The examples in this book will not run on the production
release of IE5. The production implementation of the old dialect is described in http://msdn.microsoft.com/xml/XSLGuide/conformance.asp. |
2.1.1 Some simple examples
Consider the following XML file hello.xml obtained from the XML 1.0
Recommendation and modified to declare an associated stylesheet:
01 <?xml version="1.0"?> 02 <?xml-stylesheet type="text/xsl" href="hello.xsl"?> 03 <greeting>Hello world.</greeting> |
|
|
We will use this simple file as the source of information for our transformation.
Note
that the stylesheet association processing instruction in line 2 refers to a stylesheet
with
the name "hello.xsl" of type XSL. Recall that an XSLT processor is not
obliged to respect the stylesheet association preference, so let us first use a standalone
XSLT processor with the following stylesheet hellohtm.xsl:
This file looks like a simple XHTML file: an XML file using the HTML vocabulary.
Indeed,
it is just that, but we are allowed to inject into the instance XSLT instructions
using the
prefix for the XSLT vocabulary declared on line 3. We can use any XML file as an XSLT
stylesheet provided it declares the XSLT vocabulary within and indicates the version
of XSLT
being used. Any prefix can be used for XSLT instructions, though convention often
sees
xsl: as the prefix value.
Line 7 contains the only XSLT instruction in the instance. The xsl:value-of
instruction uses an XPath expression in the select= attribute to calculate a
string value from our source information. XPath views the source hierarchy using
parent/child relationships. The XSLT processor's initial focus is the root of the
document,
which is considered the parent of the document element. Our XPath expression value
"greeting" selects the child named "greeting" from the current
focus, thus returning the value of the document element named "greeting" from
the instance.
Using an MS-DOS command-line invocation to execute the standalone processor, we see the following result:
01 X:\samp>xt hello.xml hellohtm.xsl hellohtm.htm 02 X:\samp>type hellohtm.htm 03 <html> 04 <head> 05 <title>Greeting</title> 06 </head> 07 <body> 08 <p>Words of greeting:<br> 09 <b><i><u>Hello world.</u></i></b> 10 </p> 11 </body> 12 </html> 13 14 X:\samp> |
|
|
Note how the end result contains a mixture of the stylesheet markup and the source instance content, without any use of the XSLT vocabulary. The processor has recognized the use of HTML by the name of the document element and has engaged SGML lexical conventions.
The SGML lexical conventions are evidenced on line 8 where the <br>
empty element has been serialized without the XML lexical convention for the closing
delimiter. This corresponds to line 6 of our stylesheet in Example 2-2 where this element is marked up as <br/>
according to XML rules. Our inputs are always XML but the XSLT processor may recognize
the
output as being HTML and serialize the result following SGML rules.
Consider next the following explicitly-declared XSLT file hello.xsl to
produce XML output using the HTML vocabulary, thus the output is serialized as XHTML:
This file explicitly declares the document element of an XSLT stylesheet with the
requisite XSLT namespace and version declarations. Line 7 declares the output to follow
XML
lexical conventions and that the XML declaration is to be omitted from the serialized
result. Lines 9 through 11 declare the content of the result that is added when the
source
information position matches the XPath expression in the match= attribute on
line 9. The value of "/" matches the root of the document, hence, this refers
to the XSLT processor's initial focus.
The result we specify on line 10 wraps our source information in the HTML elements without the boilerplate used in the previous example. Line 13 ends the formal specification of the stylesheet content.
Using an MS-DOS command-line invocation to execute the XT processor we see the following result:
01 X:\samp>xt hello.xml hello.xsl hello.htm 02 03 X:\samp>type hello.htm 04 <b><i><u>Hello world.</u></i></b> 05 X:\samp> |
|
|
Using a non-XML-aware browser to view the resulting HTML in Example 2-5 we see the following on the canvas (the child window is opened using the View/Source menu item):

|
|
|
Using an XML-aware browser recognizing the W3C stylesheet association processing instruction in Example 2-1, the canvas is painted with the HTML resulting from application of the stylesheet (the child window is opened using the View/Source menu item):

|
|
|
The canvas content matches what the non-XML browser rendered in Figure 2-1. Note that View/Source displays the raw XML source and not the transformed XHTML result of applying the stylesheet.
| Note: |
I found it very awkward when first using browser-based stylesheets to diagnose problems in my stylesheets. Without access to the intermediate results of transformation, it is often impossible to ascertain the nature of the faulty HTML generation. One of the free resources found on the Crane Softwrights Ltd. web site is a script for standalone command-line invocation of the MSXML XSLT processor. This script is useful for diagnosing problems by revealing the result of transformation. This script has also been used extensively by some to create static HTML snapshots of their XML for delivery to non-XML-aware browsers. |
This is a prose version of an excerpt from the book "Practical Transformation Using XSLT and XPath" (Eighth Edition ISBN 1-894049-05-5 at the time of this writing) published by Crane Softwrights Ltd., written by G. Ken Holman; this excerpt was edited by Stan Swaren, and reviewed by Dave Pawson.
2.1.2 Some more complex examples
The following more complex examples are meant merely as illustrations of some of the powerful facilities and techniques available in XSLT. These samples expose concepts such as variables, functions, and process control constructs a stylesheet writer uses to effect the desired result, but does not attempt any tutelage in their use.
| Note: |
This subsection can be skipped entirely, or, for quick exposure to some of the facilities available in XSLT and XPath, only briefly reviewed. In the associated narratives, I've avoided the precise terminology that hasn't yet been introduced and I overview the stylesheet contents and processor behaviors in only broad terms. Subsequent subsections of this chapter review some of the basic terminology and design approaches. I hope not to frighten the reader with the complexity of these examples, but it is important to realize that there are more complex operations than can be illustrated using our earlier three-line source file example. The complexity of your transformations will dictate the complexity of the stylesheet facilities being engaged. Simple transformations can be performed quite simply using XSLT, but not all of us have to meet only simple requirements. |
The following XML source information in prod.xml is used to produce two very
dissimilar renderings:
Lines 2 through 11 describe the document model for the sales information. Lines 14
and 15
summarize product description information and have unique identifiers according to
the
ID/IDREF rules. Lines 16 through 23 summarize customer purchases
(product sales), each entry referring to the product having been sold by use of the
idref= attribute. Not all customers have been sold all products.
Consider the following two renderings of the same data using two orientations, each produced with different stylesheets:

|
|
|
Note how the same information is projected into a table orientation on the left canvas and a list orientation on the right canvas. The one authored order is delivered in two different presentation orders. Both results include titles from boilerplate text not found in the source. The table information on the left includes calculations of the sums of quantities in the columns, generated by the stylesheet and not present explicitly in the source.
The implicit stylesheet prod-imp.xsl is an XHTML file utilizing the XSLT
vocabulary for instructions to fill in the one result template by pulling data from
the
source:
Recall that a stylesheet is oriented according to the desired result, producing the
result
in result parse order. The entire document is an HTML file whose document element
begins on
line 3 and ends on line 30. The XSLT namespace and version declarations are included
in the
document element. The naming of the document element as "html" triggers the default
use of
HTML result tree serialization conventions. Lines 5 and 6 are fixed boilerplate information
for the mandatory <title> element.
Lines 7 through 29 build the result table from the content. A single header row
<th> is generated in lines 9 through 12, with the columns of that row
generated by traversing all of the <product> elements of the source. The
focus moves on line 11 to each <product> source element in turn and the
markup associated with the traversal builds each <td> result element. The
content of each column is specified as ".", which for an element evaluates to
the string value of that element.
Having completed the table header, the table body rows are then built, one at a time
traversing each <cust> child of a <record> child of
the <sales> child of the root of the document, according to the XPath
expression "/sales/record/cust". The current focus moves to the
<cust> element for the processing on lines 15 through 21. A local scope
variable is bound on line 15 with the tree location of the current focus (note how
this
instruction uses the same XPath expression as on line 11 but with a different result).
A
table row is started on line 16 with the leftmost column calculated from the
num= attribute of the <cust> element being processed.
The stylesheet then builds in lines 17 through 20 a column for each of the same columns
created for the table header on line 10. The focus moves to each product in turn for
the
processing of lines 18 through 20. Each column's value is then calculated with the
expression "$customer/prodsale[@idref=current()/@id]", which could be expressed
as follows "from the customer location bound to the variable $customer, from
all of the <prodsale> children of that customer, find that child whose
idref= attribute is the value of the id= attribute of the focus
element." When there is no such child, the column value is empty and processing continues.
As many columns are produced for a body row as for the header row and our output becomes
perfectly aligned.
Finally, lines 23 through 28 build the bottom row of the table with the totals calculated
for each product. After the boilerplate leftmost column, line 24 uses the same
"//product" expression as on lines 10 and 17 to generate the same number of
table columns. The focus changes to each product for lines 25 through 28. A local
scope
variable is bound with the focus position in the tree. Each column is then calculated
using
a built-in function as the sum of all <prodsale> elements that reference
the column being totaled. The XPath designers, having provided the sum()
function in the language, keep the stylesheet writer from having to implement complex
counting and summing code; rather, the writer merely declares the need for the summed
value
to be added to the result on demand by using the appropriate XPath expression.
The file prod-exp.xsl is an explicit XSLT stylesheet with a number of result
templates for handling source information:
The document element on line 3 includes the requisite declarations of the language namespace and the version being used in the stylesheet. The children of the document element are the template rules describing the source tree event handlers for the transformation. Each event handler associates a template with an event trigger described by an XPath expression.
Lines 6 through 10 describe the template rule for processing the root of the document,
as
indicated by the "/" trigger in the match= attribute on line 6.
The result document element and boilerplate is added to the result tree on lines 7
and 8.
Line 9 instructs the XSLT processor in <xsl:apply-templates> to visit all
<record> element children of the <sales> document
element, as specified in the select= attribute. For each location visited, the
processor pushes that location through the stylesheet, thus triggering the template
of
result markup it can match for each location.
Lines 12 and 13 describe the result markup when matching a <record>
element. The focus moves to the <record> element being visited. The
template rule on line 13 adds the markup for the HTML unordered list <ul>
element to the result tree. The content of the list is created by instructing the
processor
to visit all children of the focus location (implicitly by not specifying any
select= attribute) and apply the templates of result markup it triggers for
each child. The only children of <record> are <cust>
elements.
The stylesheet does not provide any template rule for the <cust>
element, so built-in template rules automatically process the children of each location
being visited in turn. Implicitly, then, our source information is being traversed
in the
depth-first order, visiting the locations in parse order and pushing each location
through
any template rules that are then found in the stylesheet. The children of the
<cust> elements are <prodsale> elements.
The stylesheet does provide a template rule in lines 15 through 20 to handle a
<prodsale> element when it is pushed, so the XSLT processor adds the
markup triggered by that rule to the result. The focus changes when the template rule
handles it, thus, lines 16, 18, and 20 each pull information relative to the
<prodsale> element, respectively: the parent's num=
attribute (the <cust> element's attribute); the string value of the
target element being pointed to by the <prodsale> element's
idref= attribute (indirectly obtaining the <product>
element's value); and the value of the <prodsale> element itself.
This is a prose version of an excerpt from the book "Practical Transformation Using XSLT and XPath" (Eighth Edition ISBN 1-894049-05-5 at the time of this writing) published by Crane Softwrights Ltd., written by G. Ken Holman; this excerpt was edited by Stan Swaren, and reviewed by Dave Pawson.
2.2 Syntax basics: Stylesheets, Templates, Instructions
Next we'll look at some basic terminology both helpful in understanding the principles of writing an XSLT stylesheet and recognizing the constructs used therein. This section is not meant as tutelage for writing stylesheets, but only as background information, nomenclature, and practice guidelines.
| Note: |
I use two pairs of diametric terms not used as such in the XSLT Recommendation itself: explicit/implicit stylesheets and push/pull design approaches. Students of my instructor-led courses have found these distinctions helpful even though they are not official terms. Though these terms are documented here with apparent official status, such status is not meant to be conferred. |
2.2.1 Explicitly declared stylesheets
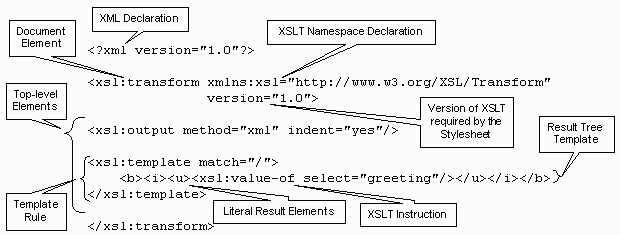
An explicitly declared XSLT stylesheet is comprised of a distinct wrapper element
containing the stylesheet specification. This wrapper element must be an XSLT instruction
named either stylesheet or transform, thus it must be qualified by
the prefix associated with the XSLT namespace URI. This wrapper element is the document
element in a standalone stylesheet, but may in other cases be embedded inside an XML
document.
|
|
|
The XML declaration is consumed by the XML processor embedded within the XSLT processor, thus the XSLT processor never sees it. The wrapper element must include the XSLT namespace and version declarations for the element to be recognized as an instruction.
The children of the wrapper element are the top-level elements, comprised of global constructs, serialization information, and certain maintenance instructions. Template rules supply the stylesheet behavior for matching source tree conditions. The content of a template rule is a result tree template containing both literal result elements and XSLT instructions.
The example above has only a single template rule, that being for the root of the document.
2.2.2 Implicitly declared stylesheets
The simplest kind of XSLT stylesheet is an XML file implicitly representing the entire outcome of transformation. The result vocabulary is arbitrary, and the stylesheet tree forms the template used by the XSLT processor to build the result tree. If no XSLT or extension instructions are found therein, the stylesheet tree becomes the result tree. If instructions are present, the processor replaces the instructions with the outcomes of their execution.

|
|
|
The XML declaration is consumed by the XML processor embedded within the XSLT processor, thus the XSLT processor never sees it. The remainder of the file is considered the result tree template for an implicit rule for the root of the document, describing the shape of the entire outcome of the transformation.
The document element is named "html" and contains the namespace and version
declarations of the XSLT language. Any element type within the result tree template
that is
qualified by the prefix assigned to the XSLT namespace URI is recognized as an XSLT
instruction. No extension instruction namespaces are declared, thus all other element
types
in the instance are literal result elements. Indeed, the document element is a literal
result element as it, too, is not an instruction.
2.2.3 Stylesheet requirements
Every XSLT stylesheet must identify the namespace prefix used therein for XSLT
instructions. The default namespace cannot be used for this purpose. The namespace
URI
associated with the prefix must be the value
http://www.w3.org/1999/XSL/Transform . It is a common practice to use the
prefix xsl to identify the XSLT vocabulary, though this is only convention and
any valid prefix can be used.
XSLT processor extensions are outside the scope of the XSLT vocabulary, so other URI values must be used to identify extensions.
The stylesheet must also declare the version of XSLT required by the instructions
used
therein. The attribute is named version and must accompany the namespace
declaration in the wrapper element instruction as
version="version-number" . In an implicit stylesheet where the XSLT
namespace is declared in an element that is not an XSLT instruction, the namespace-qualified
attribute declaration must be used as
prefix:version="version-number" .
The version number is a numeric floating-point value representing the latest version of XSLT defining the instructions used in the stylesheet. It need not declare the most capable version supported by the XSLT processor.
2.2.4 Instructions and literal result elements
XSLT instructions are only detected in the stylesheet tree and are not detected in the source tree. Instructions are specified using the namespace prefix associated with the XSLT namespace URI. The XSLT Recommendation describes the behavior of the XSLT processor for each of the instructions defined based on the instruction's element type (name).
Top-level instructions are considered and/or executed by the XSLT processor before processing begins on the source information. For better performance reasons, a processor may choose to not consider a top-level instruction until there is need within the stylesheet to use it. All other instructions are found somewhere in a result tree template and are not executed until that point at which the processor is asked to add the instruction to the result tree. Instructions themselves are never added to the result tree.
Some XSLT instructions are control constructs used by the processor to manage our stylesheets. The wrapper and top-level elements declare our globally scoped constructs. Procedural and process-control constructs give us the ability to selectively add only portions of templates to the result, rather than always adding an entire template. Logically-oriented constructs give us facilities to share the use of values and declarations within our own stylesheet files. Physically-oriented constructs give us the power to share entire stylesheet fragments.
Other XSLT instructions are result tree value placeholders. We declare how a value is calculated by the processor, or obtained from a source tree, or both calculated by the processor from a value from a source tree. The value calculation is triggered when the XSLT processor is about to add the instruction to the result tree. The outcome of the calculation (which may be nothing) is added to the result tree.
All other instructions engage customized non-standard behaviors and are specified using extension elements in a standardized fashion. These elements use namespace prefixes declared by our stylesheets to be instruction prefixes. Extension instructions may be either control constructs or result tree value placeholders.
Consider the simple example in our stylesheets used earlier in this chapter where the following instruction is used:
01 <xsl:value-of select="greeting"/> |
|
|
This instruction uses the select= attribute to specify the XPath expression
of some value to be calculated and added to the result tree. When the expression is
a
location in the source tree, as is this example, the value returned is the value of
the
first location identified using the criteria. When that location is an element, the
value
returned is the concatenation of all of the #PCDATA text contained therein.
This example instruction is executed in the context of the root of the source document
being the focus. The child of the root of the document is the document element. The
expression requests the value of the child named "greeting " of the root of the
document, hence, the value of the document element named "greeting ". For any
source document where "greeting " is not the document element, the value
returned is the empty string. For any source document where it is the document element,
as
is our example, the value returned is the concatenation of all #PCDATA text in the
entire
instance.
A literal result element is any element in a stylesheet that is not a top-level element and is not either an XSLT instruction or an extension instruction. A literal result element can use the default namespace or any namespace not declared in the stylesheet to be an instruction namespace.
When the XSLT processor reads the stylesheet and creates the abstract nodes in the stylesheet tree, those nodes that are literal result elements represent the nodes that are added to the result tree. Though the definition of those nodes is dictated by the XML syntax in the stylesheet entity, the syntax used does not necessarily represent the syntax that is serialized from the result tree nodes created from the stylesheet nodes.
Literal result elements marked up in the stylesheet entity may have attributes that are targeted for the XML processor used by the XSLT processor, targeted for the XSLT processor, or targeted for use in the result tree. Some attributes are consumed and acted upon as the stylesheet file is processed to build the stylesheet tree, while the others remain in the stylesheet tree for later use. Those literal result attributes remaining in the stylesheet tree that are qualified with an instruction namespace are acted on when they are asked to be added to the result tree.
2.2.5 Templates and template rules
Many XSLT instructions are container elements. The collection of literal result elements and other instructions being contained therein comprises the XSLT template for that instruction. A template can contain only literal result elements, only instruction elements, or a mixture of both. The behavior of the stylesheet can ask that a template be added to the result tree, at which point the nodes for literal result elements are added and the nodes for instructions are executed.
Consider again the simple example in our stylesheets used earlier in this chapter where the following template is used:
01 <b><i><u><xsl:value-of select="greeting"/></u></i></b> |
|
|
This template contains a mixture of literal result elements and an instruction element.
When the XSLT processor adds this template to the result tree, the nodes for the
<b> , <i> and <u> elements are
simply added to the tree, while the node for the xsl:value-of instruction
triggers the processor to add the outcome of instruction execution to the tree.
A template rule is a declaration to the XSLT processor of a template to be added to the result tree when certain conditions are met by source locations visited by the processor. Template rules are either top-level elements explicitly written in the stylesheet or built-in templates assumed by the processor and implicitly available in all stylesheets.
The criteria for adding a written template rule's template to the result tree are
specified in a number of attributes, one of which must be the match= attribute.
This attribute is an XPath pattern expression, which is a subset of XPath expressions
in
general. The pattern expression describes preconditions of source tree nodes. The
stylesheet
writer is responsible for writing the preconditions and other attribute values in
such a way
as to unambiguously provide a single written or built-in template for each of the
anticipated source tree conditions.
In an implicitly declared stylesheet, the entire file is considered the template for the template rule for the root of the document. This template rule overrides the built-in rule implicitly available in the XSLT processor.
Back to the simple example in our explicitly declared stylesheet used earlier in this chapter, the following template rule is declared:
01 <xsl:template match="/"> 02 <b><i><u><xsl:value-of select="greeting"/></u></i></b> 03 </xsl:template> |
|
|
This template rule defines the template to be added to the result tree when the root of the document is visited. This written rule overrides the built-in rule implicitly available in the XSLT processor. The template is the same template we were discussing earlier: a set of result tree nodes and an instruction.
The XSLT processor begins processing by visiting the root of the document. This gives control to the stylesheet writer. Either the supplied template rule or built-in template rule for the root of the document is processed, based on what the writer has declared in the stylesheet. The writer is in complete control at this early stage and all XSLT processor behavior is dictated what the writer asks to be calculated and where the writer asks the XSLT processor to visit.
2.2.6 Approaches to stylesheet design
The last discussion in this two-chapter introduction regards how to approach using templates and instructions when writing a stylesheet. Two distinct approaches can be characterized. Choosing which approach to use when depends on your own preferences, the nature of the source information, and the nature of the desired result.
| Note: |
I refer to these two approaches as either stylesheet-driven or data-driven, though the former might be misconstrued. Of course all results are stylesheet-driven because the stylesheet dictates what to do, so the use of the term involves some nuance. By stylesheet-driven I mean that the order of the result is a result of the stylesheet tree having explicitly instructed the adding of information to the result tree. By data-driven I mean that the order of the result is a result of the source tree ordering having dictated the adding of information to the result tree. |
2.2.6.1 Pulling the input data
When the stylesheet writer knows the location of and order of data found in the source tree, and the writer wants to add to the result a value from or collection of that data, then information can be pulled from the source tree on demand. Two instructions are provided for this purpose: one for obtaining or calculating a single string value to add to the result; and one for adding rich markup to the result based on obtaining as many values as may exist in the tree.
The writer uses the <xsl:value-of select="XPath-expression"/>
instruction in a stylesheet's element content to calculate a single value to be added
to the
result tree. The instruction is always empty and therefore does not contain a template.
This
value calculated can be the result of function execution, the value of a variable,
or the
value of a node selected from the source tree. When used in the template of various
XSLT
instructions the outcome becomes part of the value of a result element, attribute,
comment,
or processing instruction.
Note there is also a shorthand notation called an "attribute value template" that
allows
the equivalent to <xsl:value-of> to be used in a stylesheet's attribute
content.
To iterate over locations in the source tree, the <xsl:for-each
select="XPath-node-set-expression"> instruction defines a template to
be processed for each instance, possibly repeated, of the selected locations. This
template
can contain literal result elements or any instruction to be executed. When processing
the
given template, the focus of the processor's view of the source tree shifts to the
location
being visited, thus providing for relative addressing while moving through the
information.
These instructions give the writer control over the order of information in the result. The data is being pulled from the source on demand and added to the result tree in the stylesheet-determined order. When collections of nodes are iterated, the nodes are visited in document order. This implements a stylesheet-driven approach to creating the result.
An implicitly-declared stylesheet is obliged to use only these "pull" instructions and must dictate the order of the result with the above instructions in the lone template.
2.2.6.2 Pushing the input data
The stylesheet writer may not know the order of the data found in the source tree, or may want to have the source tree dictate the ordering of content of the result tree. In these situations, the writer instructs the XSLT processor to visit source tree nodes and to apply to the result the templates associated with the nodes that are visited.
The <xsl:apply-templates select="XPath-node-expression">
instruction visits the source tree nodes described by the node expression in the
select= attribute. The writer can choose any relative, absolute, or arbitrary
location or locations to be visited.
Each node visited is pushed through the stylesheet to be caught by template rules. Template rules specify the template to be processed and added to the result tree. The template added is dictated by the template rule matched for the node being pushed, not by a template supplied by the instruction when a node is being pulled. This distinguishes the behavior as being a data-driven approach to creating the result, in that the source determines the ultimate order of the result.
An implicitly-declared stylesheet can only push information through built-in template rules, which is of limited value. As well, the built-in rules can be mimicked entirely by using pull constructs, thus they need never be used. There is no room in the stylesheet to declare template rules in an implicitly-declared stylesheet since there is no wrapper stylesheet instruction.
An explicitly-declared stylesheet can either push or pull information because there is room in the stylesheet to define the top-level elements, including any number of template rules required for the transformation.
Putting it all together
We are not obliged to use only one approach when we write our stylesheets. It is very appropriate to push where the order is dictated by the source information and to pull when responding to a push where the order is known by the stylesheet. The most common use of this combination in a template is localized pull access to values that are relative to the focus being matched by nodes being pushed.
Note that push-oriented stylesheets more easily accommodate changes to the data and are more easily exploited by others who wish to reuse the stylesheets we write. The more granularity we have in our template rules, the more flexibly our stylesheets can respond to changes in the order of data. The more we pull data from our source tree, the more dependent we are on how we have coded the access to the information. The more we push data through our stylesheet, the less that changes in our data impact our stylesheet code.
Look again at the examples discussed earlier in this article and analyze the use of the above pull and push constructs to meet the objectives of the transformations.
These introductions and samples in this article have set the context, and only scratch the surface of the power of XSLT to effect the transformations we need when working with our structured information.
XML.com has continuing coverage and tutorials about XPath and XSLT in its regular column, Transforming XML.
This is a prose version of an excerpt from the book "Practical Transformation Using XSLT and XPath" (Eighth Edition ISBN 1-894049-05-5 at the time of this writing) published by Crane Softwrights Ltd., written by G. Ken Holman; this excerpt was edited by Stan Swaren, and reviewed by Dave Pawson.